Dieser Beitrag ist im Oktober 2016 geschrieben worden.
Am Wochenende habe ich mir das Video von Tim Gross' Vortrag auf der Velocity 2016 angesehen. Er stellt darin den sogenannten Autopilot Pattern vor, welchen z. B. Projekte wie Containerpilot oder Habitat implementieren. Dabei geht es darum, dass Applikationsentwickler auch die Orchestrierung der von ihnen implementierten Applikationen übernehmen und diese nicht einem externen Orchestrator überlassen.
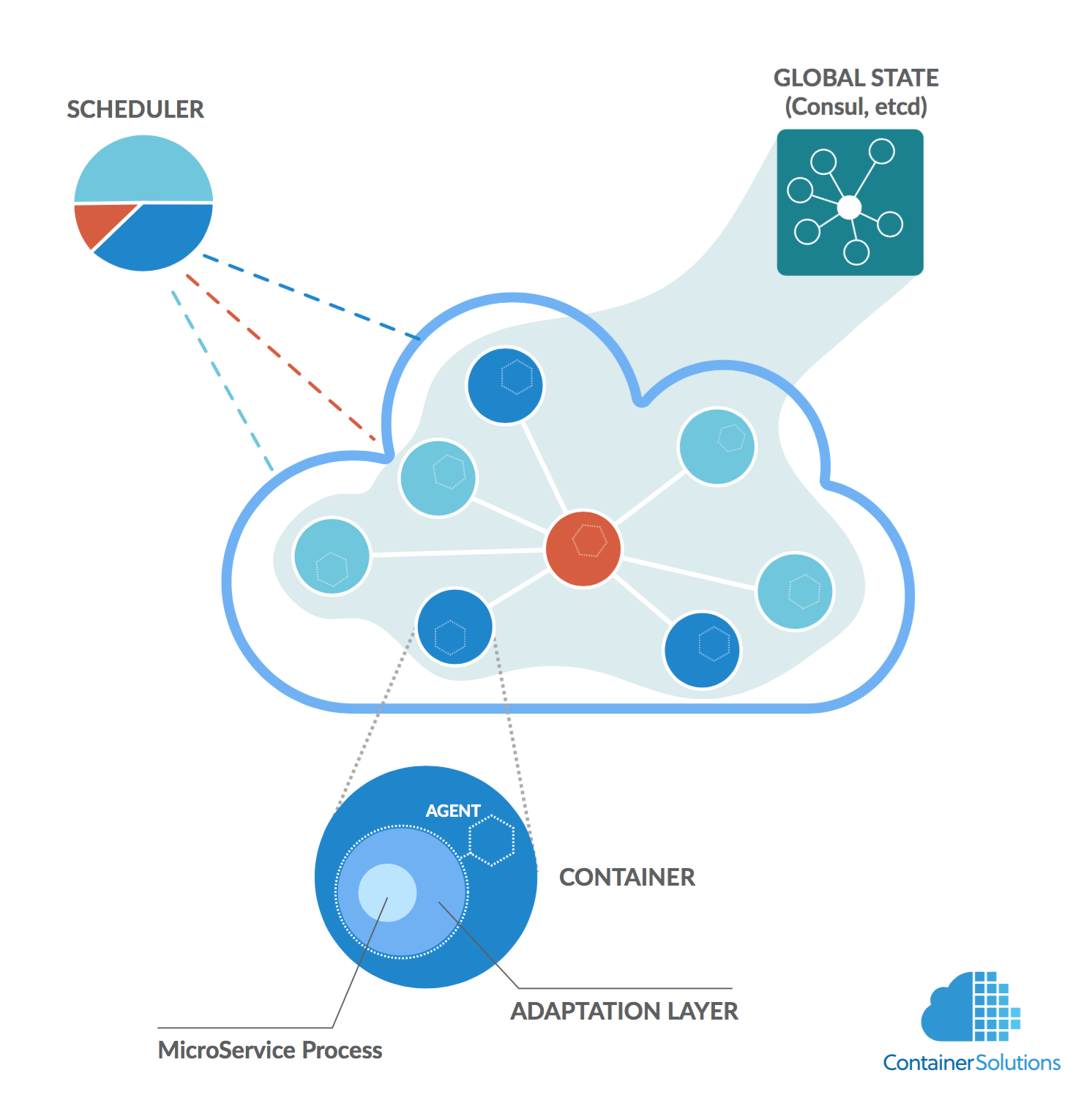
Natürlich habe ich die im Vortrag gezeigten Beispiele gleich mal nachvollzogen, um zu sehen, ob sie auch wirklich funktionieren. Tim Gross beschreibt i. W. zwei Anwendungen:
- Eine "stateless" Applikation mit nginx als Loadbalancer und nodejs Applikation
- Eine "stateful" Applikation mit mysql in einer Master/Slave-Replikation
Im ersten Fall verwendet er consul-template um die Konfiguration von nginx je nach Status in consul, welches hier als dynamisch veränderbare "source of truth" verwendet wird - umschreiben zu können. Konkret führt ein fehlgeschlagener Health-Check dazu, dass ein Member aus der Loadbalancing-Konfiguration ausgetragen wird. Bei einem erfolgreichen Health-Check, wird ein Member auch wieder eingetragen. Hinzukommende Member (z. B. per docker-compose scale sales=4) melden sich über Consul als "healthy" und werden ebenfalls in die Loadbalancing-Konfiguration aufgenommen.
Da die Applikation "stateless" ist, muss kein Content kopiert und keine Replikation konfiguriert werden. Aber die nginx-Konfiguration muss umgeschrieben werden - und zwar "eventbasiert" je nach dem ob Member hinzukommen oder wegfallen. Die Event-Hooks "preStart", "health" und "onChange" übernehmen dies, wenn die Applikation nach dem "Autopilot Pattern" implementiert wurde.
Bei Applikationen, die "stateful" sind, stellt sich die Situation etwas komplizierter dar. Tim Gross hatte dafür ein Setup mit Percona MySQL ausgewählt:
root@ec057038-51aa-ed39-ffc9-dd88a5a20198:~/mysql# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b856fef6c230 autopilotpattern/mysql "containerpilot mysql" 2 minutes ago Up 2 minutes 3306/tcp mysql_mysql_1
8ee4d50975a9 autopilotpattern/consul:0.7r0.7 "/usr/local/bin/conta" 2 minutes ago Up 2 minutes 53/tcp, 53/udp, 8300-8302/tcp, 8400/tcp, 8301-8302/udp, 0.0.0.0:8500->8500/tcp mysql_consul_1
Gestartet werden ein Container mit Consul und einer mit Percona MySQL. Da es sich um den ersten MySQL-Server handelt, wird er automatisch zum Master:
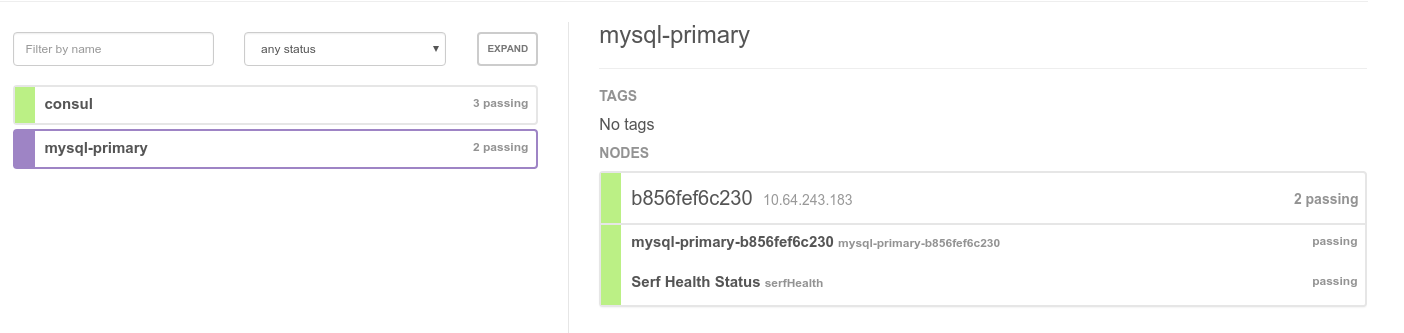
Durch hinzufügen weiterer MySQL-Nodes (z. B. durch docker-compose scale mysql=2) meldet sich der dort installierte Containerpilot bei consul, teilt dem neuen Node den Namen des aktuellen Masters mit woraufhin dieser die Replikation aufsetzt:
2016-10-24 12:57:43 63733 [Note] Event Scheduler: Loaded 0 events
2016-10-24 12:57:43 63733 [Note] mysqld: ready for connections.
Version: '5.6.31-77.0-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 Percona Server (GPL), Release 77.0, Revision 5c1061c
2016-10-24 12:57:46 63733 [Warning] Neither --relay-log nor --relay-log-index were used; so replication may break when this MySQL server acts as a slave and has his hostname changed!! Please use '--relay-log=mysqld-relay-bin' to avoid this problem.
2016-10-24 12:57:46 63733 [Note] 'CHANGE MASTER TO executed'. Previous state master_host='', master_port= 3306, master_log_file='', master_log_pos= 4, master_bind=''. New state master_host='10.64.243.183', master_port= 3306, master_log_file='', master_log_pos= 4, master_bind=''.
2016-10-24 12:57:46 63733 [Warning] Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information.
2016-10-24 12:57:46 63733 [Warning] Slave SQL: If a crash happens this configuration does not guarantee that the relay log info will be consistent, Error_code: 0
2016-10-24 12:57:46 63733 [Note] Slave SQL thread initialized, starting replication in log 'FIRST' at position 0, relay log './mysqld-relay-bin.000001' position: 4
2016-10-24 12:57:46 63733 [Note] Slave I/O thread: connected to master 'repluser@10.64.243.183:3306',replication started in log 'FIRST' at position 4
frm
2016/10/24 12:57:40 161024 12:57:40 [01] ...done
Im consul stellt sich das dann so dar:
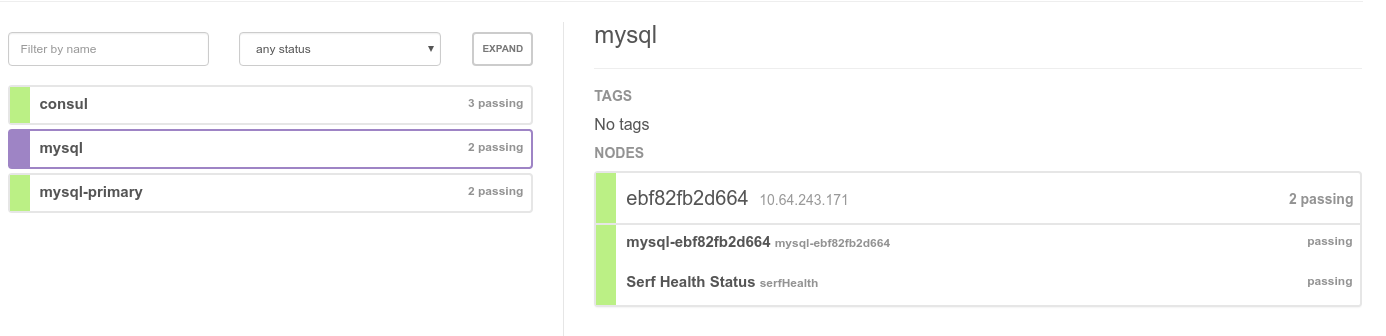
Fällt der Master aus, sorgt Containerpilot mit Hilfe von consul dafür, dass einer der bisherigen Slaves zum Master wird und die überlebenden Slaves diesen als Replikationsquelle verwenden.
root@ec057038-51aa-ed39-ffc9-dd88a5a20198:~/mysql# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c7224e00c8ec autopilotpattern/mysql "containerpilot mysql" 5 minutes ago Up 5 minutes 3306/tcp mysql_mysql_4
b0c11b77dc92 autopilotpattern/mysql "containerpilot mysql" 5 minutes ago Up 5 minutes 3306/tcp mysql_mysql_5
f8496ef6618e autopilotpattern/mysql "containerpilot mysql" 5 minutes ago Up 5 minutes 3306/tcp mysql_mysql_3
ebf82fb2d664 autopilotpattern/mysql "containerpilot mysql" About an hour ago Up About an hour 3306/tcp mysql_mysql_2
b856fef6c230 autopilotpattern/mysql "containerpilot mysql" About an hour ago Up About an hour 3306/tcp mysql_mysql_1
8ee4d50975a9 autopilotpattern/consul:0.7r0.7 "/usr/local/bin/conta" About an hour ago Up About an hour 53/tcp, 53/udp, 8300-8302/tcp, 8400/tcp, 8301-8302/udp, 0.0.0.0:8500->8500/tcp mysql_consul_1
488dc883efd1 percona/pmm-server:1.0.4 "/opt/entrypoint.sh" 4 weeks ago Up 4 weeks 0.0.0.0:80->80/tcp, 443/tcp pmm-server
e66cb4c8d980 percona/pmm-server:1.0.4 "/bin/true" 4 weeks ago Created 80/tcp, 443/tcp pmm-data
root@ec057038-51aa-ed39-ffc9-dd88a5a20198:~/mysql# docker rm -f b856fef6c230
b856fef6c230
In der GUI von consul sieht das so aus. Der "alte" Master ist noch als "critical" eingetragen. Der neue Master ist schon fertig:
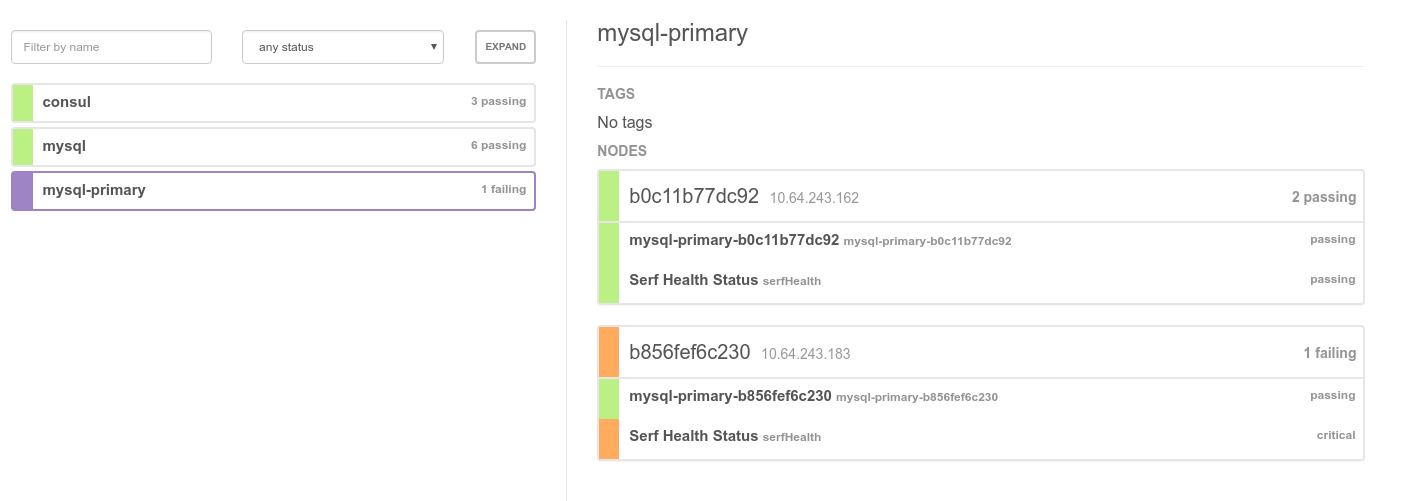
Auf dem entsprechenden Node steht dies im Log:
2016/10/24 14:10:44 2016/10/24 14:10:44 [INFO] memberlist: Marking b856fef6c230 as failed, suspect timeout reached (3 peer confirmations)
2016/10/24 14:10:44 2016/10/24 14:10:44 [INFO] serf: EventMemberFailed: b856fef6c230 10.64.243.183
2016/10/24 14:10:44 2016/10/24 14:10:44 [INFO] memberlist: Suspect b856fef6c230 has failed, no acks received
2016/10/24 14:10:45 INFO manage [on_change] Executing failover with candidates: [u'10.64.243.162', u'10.64.243.163', u'10.64.243.171', u'10.64.243.160']
2016/10/24 14:10:45 WARNING: Using a password on the command line interface can be insecure.
2016/10/24 14:10:45 # Checking privileges.
2016/10/24 14:10:45 # Checking privileges on candidates.
2016/10/24 14:10:45 # Performing failover.
2016/10/24 14:10:45 # Candidate slave 10.64.243.162:3306 will become the new master.
2016/10/24 14:10:45 # Checking slaves status (before failover).
2016/10/24 14:10:45 # Preparing candidate for failover.
2016/10/24 14:10:45 # Creating replication user if it does not exist.
2016/10/24 14:10:45 # Stopping slaves.
2016/10/24 14:10:45 # Performing STOP on all slaves.
2016/10/24 14:10:45 # Switching slaves to new master.
2016/10/24 14:10:45 # Disconnecting new master as slave.
2016/10/24 14:10:45 # Starting slaves.
2016/10/24 14:10:45 # Performing START on all slaves.
2016/10/24 14:10:45 # Checking slaves for errors.
2016/10/24 14:10:45 # Failover complete.
2016/10/24 14:10:45 #
2016/10/24 14:10:45 # Replication Topology Health:
2016/10/24 14:10:45 +----------------+-------+---------+--------+------------+---------+
2016/10/24 14:10:45 | host | port | role | state | gtid_mode | health |
2016/10/24 14:10:45 +----------------+-------+---------+--------+------------+---------+
2016/10/24 14:10:45 | 10.64.243.162 | 3306 | MASTER | UP | ON | OK |
2016/10/24 14:10:45 | 10.64.243.160 | 3306 | SLAVE | UP | ON | OK |
2016/10/24 14:10:45 | 10.64.243.163 | 3306 | SLAVE | UP | ON | OK |
2016/10/24 14:10:45 | 10.64.243.171 | 3306 | SLAVE | UP | ON | OK |
2016/10/24 14:10:45 +----------------+-------+---------+--------+------------+---------+
2016/10/24 14:10:45 # ...done.
2016/10/24 14:10:45 INFO manage [on_change] node b0c11b77dc92 is primary after failover
2016/10/24 14:10:45 INFO manage rewriting ContainerPilot config: {"preStart": "python /usr/local/bin/manage.py", "tasks": [{"frequency": "5m", "command": "python /usr/local/bin/manage.py snapshot_task", "name": "snapshot_check", "timeout": "10m"}], "logging": {"level": "{{ if .LOG_LEVEL }}{{ .LOG_LEVEL }}{{ else }}INFO{{ end }}"}, "coprocesses": [{"restarts": "unlimited", "command": ["/usr/local/bin/consul", "agent", "-data-dir=/data", "-config-dir=/config", "-rejoin", "-retry-join", "consul.svc.f5d89e91-c2e2-e641-e780-b78365fc4843.de-gt-1.cns.tgos.de:8500", "-retry-max", "10", "-retry-interval", "10s"], "name": "consul-agent (host:{{ .CONSUL }})"}], "consul": "localhost:8500", "backends": [{"onChange": "python /usr/local/bin/manage.py on_change", "poll": 10, "name": "mysql-primary"}], "services": [{"ttl": 25, "poll": 5, "health": "python /usr/local/bin/manage.py health", "name": "mysql-primary", "port": 3306}]}
2016/10/24 14:10:45 INFO manage Reloading ContainerPilot configuration.
Jetzt muss nur noch der nun überflüssige Master im consul gelöscht und die Anzahl der Nodes wieder auf die ursprüngliche Menge skaliert werden, um den vorherigen Zustand wieder zu erreichen. Der "State" der Applikation wird in diesem Fall dadurch bewahrt, dass beim Einrichten des Masters (und danach zyklisch) eine Sicherung (in diesem Fall per xtrabackup) erzeugt und in einem "stateful" Storage (in diesem Fall ist es Manta) abgelegt wird:
Diese Backups dienen dann als Aufsetzpunkt für neu eingerichtete Nodes resp. Master:
root@ec057038-51aa-ed39-ffc9-dd88a5a20198:~/mysql# mls /hbloed/stor/triton-mysql
mysql-backup-2016-10-04T09-22-40Z
mysql-backup-2016-10-04T14-19-38Z
mysql-backup-2016-10-06T13-19-12Z
mysql-backup-2016-10-13T19-46-57Z
mysql-backup-2016-10-22T21-05-43Z
mysql-backup-2016-10-23T09-41-05Z
mysql-backup-2016-10-23T10-00-04Z
mysql-backup-2016-10-23T10-28-41Z
mysql-backup-2016-10-24T12-46-49Z
root@ec057038-51aa-ed39-ffc9-dd88a5a20198:~/mysql#
Je nach Backupfrequenz gehen also ggfs. Daten verloren (was aber auch bei "normalen" MySQL-Clustern so wäre). Die gesamte Logik für die verschiedenen Aktionen ist in manage.py implementiert.
Das bringt mich zurück zu der Frage, die bei mir aufkam als ich mir das oben genannte Video ansah. Wie sieht eigentlich die Unterstützung aus, die Docker Swarm, Kubernetes oder Mesos mitbringen, um diese Logik, die ja offenbar sogar bei "stateless" Applikationen teilweise erforderlich ist (z. B. Rekonfiguration von nginx) abzubilden? Oder anders gefragt: Muss die genannte Logik in jedem Fall implementiert werden - egal für welche Art von Orchestrierung man sich entscheidet? Im Zusammenhang von Kubernetes habe ich von Pet Sets gelesen. Kubernetes scheint das Problem der "statefulness" über persistente volumes zu lösen (die natürlich verfügbar sein müssen). Mechanismen, die aber z. B. applikationsspezifisch Replikationen (um)konfigurieren oder aufsetzen, konnte ich bisher aber nicht entdecken. Wahrscheinlich ist das der Grund, warum der Autopilot-Pattern auch im Zusammenspiel mit zentralen Orchestrierungstools durchaus sinnvoll ist. Umgekehrt kann man vielleicht zentrale Orchestrierungstools umgehen, sofern man die eigene Applikation auf Basis des Autopilot-Pattern erstellt und dann möglichst schlanke Lösungen dafür sucht, um
- Container in Clustern zu provisionieren
- Overlay Networking zu implementieren
- Service Discovery bereitzustellen
Aber vielleicht kommen die ja auch erst noch ...