Ich hatte mir beim 1.2er Release von Nomad mal wieder die für mich interessanten Seiten in der Dokumentation angesehen. Mich interessieren dabei insbesondere
- Task-Driver (insbesondere die, die aus der Community kommen)
- Autoscaling Targets (insbesondere auch die, die aus der Community kommen)
Bisher hatte ich nur das Plugin für die Benutzung von Openstack Senlin gekannt. Weil wir Senlin in unseren Umgebungen bisher nicht im Einsatz haben, konnte ich das noch nicht ausprobieren. Nun ist ein neues Plugin für Openstack Nova aufgetaucht, welches offenbar keine weiteren Openstack Komponenten voraussetzt und deshalb von jedem User in vermutlich jeder Openstack-Umgebung verwendet werden kann.
Dazu habe ich in einem Openstack-Projekt einen Nomad-Server aufgesetzt und konfiguriert. Dazu lädt man einfach das aktuelle Binary von https://releases.hashicorp.com/nomad/ herunter, erstellt eine Konfiguration (s. u.) und legt ggfs. die erforderlichen Verzeichnisse an. Bei mir sind das immer /etc/nomad für die Konfiguration und /opt/nomad für die Daten. Gestartet wird der Prozess dann mit dem Kommando "nomad agent -config=/etc/nomad".
data_dir = "/opt/nomad"
enable_syslog = true
region = "stage"
datacenter = "stage1"
server {
enabled = true
bootstrap_expect = 1
}
consul {
server_service_name = "nomad"
}
telemetry {
collection_interval = "1s"
disable_hostname = true
prometheus_metrics = true
publish_allocation_metrics = true
publish_node_metrics = true
}
Das Log, des gestarteten Servers ist dann relativ aufschlußreich, zeigt es doch die verwendeten Adressen, Region und Datacenter, etc.:
root@nom0:~# nomad agent -config=/etc/nomad/
==> WARNING: Bootstrap mode enabled! Potentially unsafe operation.
==> Loaded configuration from /etc/nomad/nomad.hcl, /etc/nomad/server.hcl
==> Starting Nomad agent...
==> Nomad agent configuration:
Advertise Addrs: HTTP: 192.168.5.164:4646; RPC: 192.168.5.164:4647; Serf: 192.168.5.164:4648
Bind Addrs: HTTP: 0.0.0.0:4646; RPC: 0.0.0.0:4647; Serf: 0.0.0.0:4648
Client: false
Log Level: INFO
Region: stage (DC: stage1)
Server: true
Version: 1.2.1
==> Nomad agent started! Log data will stream in below:
2021-11-23T15:28:06.186Z [INFO] agent: detected plugin: name=exec type=driver plugin_version=0.1.0
2021-11-23T15:28:06.189Z [INFO] agent: detected plugin: name=qemu type=driver plugin_version=0.1.0
2021-11-23T15:28:06.189Z [INFO] agent: detected plugin: name=java type=driver plugin_version=0.1.0
2021-11-23T15:28:06.189Z [INFO] agent: detected plugin: name=docker type=driver plugin_version=0.1.0
2021-11-23T15:28:06.189Z [INFO] agent: detected plugin: name=raw_exec type=driver plugin_version=0.1.0
2021-11-23T15:28:06.206Z [INFO] nomad.raft: initial configuration: index=1 servers="[{Suffrage:Voter ID:192.168.5.164:4647 Address:192.168.5.164:4647}]"
2021-11-23T15:28:06.207Z [INFO] nomad.raft: entering follower state: follower="Node at 192.168.5.164:4647 [Follower]" leader=
2021-11-23T15:28:06.208Z [INFO] nomad: serf: EventMemberJoin: nom0.stage 192.168.5.164
2021-11-23T15:28:06.208Z [INFO] nomad: starting scheduling worker(s): num_workers=2 schedulers=["batch", "system", "sysbatch", "service", "_core"]
2021-11-23T15:28:06.209Z [WARN] nomad: serf: Failed to re-join any previously known node
2021-11-23T15:28:06.210Z [INFO] nomad: adding server: server="nom0.stage (Addr: 192.168.5.164:4647) (DC: stage1)"
2021-11-23T15:28:07.229Z [WARN] nomad.raft: heartbeat timeout reached, starting election: last-leader=
2021-11-23T15:28:07.231Z [INFO] nomad.raft: entering candidate state: node="Node at 192.168.5.164:4647 [Candidate]" term=3
2021-11-23T15:28:07.248Z [INFO] nomad.raft: election won: tally=1
2021-11-23T15:28:07.248Z [INFO] nomad.raft: entering leader state: leader="Node at 192.168.5.164:4647 [Leader]"
2021-11-23T15:28:07.249Z [INFO] nomad: cluster leadership acquired
2021-11-24T13:36:29.476Z [WARN] nomad.heartbeat: node TTL expired: node_id=7622dabe-029a-faaa-9932-7e887ff0ebb2
2021-11-24T15:06:00.517Z [WARN] nomad.heartbeat: node TTL expired: node_id=7622dabe-029a-faaa-9932-7e887ff0ebb2
2021-11-24T15:06:16.238Z [ERROR] nomad.rpc: yamux: keepalive failed: i/o deadline reached
2021-11-24T15:06:16.239Z [ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
2021-11-24T15:06:16.562Z [ERROR] nomad.rpc: yamux: keepalive failed: i/o deadline reached
2021-11-24T15:06:16.562Z [ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
2021-11-24T15:15:30.372Z [WARN] nomad.heartbeat: node TTL expired: node_id=7622dabe-029a-faaa-9932-7e887ff0ebb2
2021-11-24T15:15:39.148Z [ERROR] nomad.rpc: yamux: keepalive failed: i/o deadline reached
2021-11-24T15:15:39.149Z [ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
2021-11-24T15:15:39.599Z [ERROR] nomad.rpc: yamux: keepalive failed: i/o deadline reached
2021-11-24T15:15:39.599Z [ERROR] nomad.rpc: multiplex_v2 conn accept failed: error="keepalive timeout"
2021-11-24T15:18:12.216Z [WARN] nomad.heartbeat: node TTL expired: node_id=7622dabe-029a-faaa-9932-7e887ff0ebb2
2021-11-24T18:04:12.956Z [WARN] nomad.heartbeat: node TTL expired: node_id=e2d1e353-a2c3-9b42-56d0-5f1ed5e2b3e6
2021-11-24T18:22:22.776Z [WARN] nomad.heartbeat: node TTL expired: node_id=e2d1e353-a2c3-9b42-56d0-5f1ed5e2b3e6
==> Newer Nomad version available: 1.2.2 (currently running: 1.2.1)
Beim Nomad-Autoscaler (was ein separater Prozess ist - nicht etwa ein Plugin, wie ich zuerst dachte) geht man genauso vor: Download von https://releases.hashicorp.com/nomad-autoscaler/, erstellen verschiedener Verzeichnisse, erstellen einer Konfiguration und einer Policy (s. u.). Bei mir sind das /etc/nomad-autoscaler, /etc/nomad-autoscaler/policies und /opt/nomad-autoscaler/plugins (wo auch das os-nova Plugin abgeworfen wird). Danach kann auch der Autoscaler mit dem Kommando "nomad-autoscaler agent -plugin-dir=/opt/nomad-autoscaler/plugins -config=/etc/nomad-autoscaler -policy-dir=/etc/nomad-autoscaler/policies" gestartet werden.
nomad {
address = "http://127.0.0.1:4646"
region = "stage"
}
http {
bind_address = "192.168.5.164"
bind_port = 9999
}
apm "nomad-apm" {
driver = "nomad-apm"
}
target "os-nova" {
driver = "os-nova"
config = {
auth_url = "https://plage1.api.pco.get-cloud.io:5000/v3"
username = "tbueker"
password = "geheim"
domain_name = "pco"
project_id = "a66cd244776d4602bf88eb6a663c287a"
region_name = "RegionOne"
}
}
strategy "target-value" {
driver = "target-value"
}
Und hier die Policy, deren grobe Struktur ich der Dokumentation und verschiedenen Github-Repos entnommen habe:
scaling "worker_pool_policy" {
enabled = true
min = 1
max = 2
policy {
cooldown = "2m"
evaluation_interval = "1m"
check "cpu_allocated_percentage" {
source = "nomad-apm"
query = "percentage-allocated_cpu"
strategy "target-value" {
target = 70
}
}
target "os-nova" {
dry-run = false
# evenly_split_azs = true
stop_first = true
image_id = "e4eb6f7b-9dd7-4366-a9bf-6f9d15573368"
flavor_name = "2C-2GB-20GB"
pool_name = "nom-pool"
name_prefix = "nom-"
network_id = "9e7bd5ca-eba3-49b6-a522-9d2ea6cc52a5"
# user_data_template = "user-data.gotxt"
security_groups = "default"
availability_zones = "az1"
tags = "nom-pool,ubuntu-minimal"
node_class = "nom-pool"
node_drain_deadline = "1h"
node_drain_ignore_system_jobs = false
node_purge = true
node_selector_strategy = "least_busy"
}
}
}
Das Logfile des Nomad-Autoscalers ist ebenfalls interessant. Am Ende sieht man auch gleich das erste Scaling-Event:
root@nom0:~# nomad-autoscaler agent -plugin-dir=/opt/nomad-autoscaler/plugins -config=/etc/nomad-autoscaler -policy-dir=/etc/nomad-autoscaler/policies^C
root@nom0:~# vi /etc/nomad-autoscaler/policies/scaling.policy.hcl
root@nom0:~# nomad-autoscaler agent -plugin-dir=/opt/nomad-autoscaler/plugins -config=/etc/nomad-autoscaler -policy-dir=/etc/nomad-autoscaler/policies
2021-11-25T11:52:47.623Z [INFO] agent: Starting Nomad Autoscaler agent
2021-11-25T11:52:47.623Z [INFO] agent: Nomad Autoscaler agent configuration:
2021-11-25T11:52:47.623Z [INFO] agent:
2021-11-25T11:52:47.623Z [INFO] agent: Bind Addrs: 192.168.5.164
2021-11-25T11:52:47.623Z [INFO] agent: Log Level: info
2021-11-25T11:52:47.623Z [INFO] agent: Plugins: /opt/nomad-autoscaler/plugins
2021-11-25T11:52:47.623Z [INFO] agent: Policies: /etc/nomad-autoscaler/policies
2021-11-25T11:52:47.623Z [INFO] agent: Version: v0.3.3 (22f88bb)
2021-11-25T11:52:47.623Z [INFO] agent:
2021-11-25T11:52:47.623Z [INFO] agent: Nomad Autoscaler agent started! Log data will stream in below:
2021-11-25T11:52:47.624Z [INFO] agent.http_server: server now listening for connections: address=192.168.5.164:9999
2021-11-25T11:52:47.625Z [INFO] agent.plugin_manager: successfully launched and dispensed plugin: plugin_name=nomad-apm
2021-11-25T11:52:47.625Z [INFO] agent.plugin_manager: successfully launched and dispensed plugin: plugin_name=target-value
2021-11-25T11:52:47.625Z [INFO] agent.plugin_manager: successfully launched and dispensed plugin: plugin_name=nomad-target
2021-11-25T11:52:48.146Z [INFO] external_plugin.os-nova: discovered the following AZs: [az1], saving as default: timestamp=2021-11-25T11:52:48.146Z
2021-11-25T11:52:48.152Z [INFO] external_plugin.os-nova: discovered current microversion 2.87 for compute, making it the used one: timestamp=2021-11-25T11:52:48.152Z
2021-11-25T11:52:48.152Z [INFO] external_plugin.os-nova: completed set-up of plugin: version=v0.2.2 timestamp=2021-11-25T11:52:48.152Z
2021-11-25T11:52:48.153Z [INFO] agent.plugin_manager: successfully launched and dispensed plugin: plugin_name=os-nova
2021-11-25T11:52:48.154Z [INFO] policy_eval: starting workers: cluster=10 horizontal=10
2021-11-25T11:52:48.158Z [INFO] file_policy_source: starting file policy monitor: file=/etc/nomad-autoscaler/policies/scaling.policy.hcl name=worker_pool_policy policy_id=3655cce7-26e3-1a25-1a66-c6eabfe0aaaf
2021-11-25T11:53:48.430Z [INFO] policy_eval.worker: scaling target: id=beee4415-2c3b-2348-2a37-60a7444252dd policy_id=3655cce7-26e3-1a25-1a66-c6eabfe0aaaf queue=cluster target=os-nova from=0 to=1 reason="current count (0) below limit (1)" meta=map[]
2021-11-25T11:54:22.148Z [INFO] external_plugin.os-nova: successfully performed and verified scaling out: action=scale_out desired_count=1 pool_name=nom-pool timestamp=2021-11-25T11:54:22.147Z
Die erste Erkenntnis beim Ausprobieren war das Verwenden von Openstack Instance Tags. Diese können nur über ein Nova-Kommando (nova server-tag-set) oder über die Openstack-API gesetzt und ausgelesen werden. Im Horizon werden diese Tags nicht angezeigt.
Und zusätzlich müssen offenbar für die Verwendung von nomad-apm (der Quelle für Metriken - alternativ wird noch prometheus unterstützt) die Nomad-Clients mit einer node_class versehen werden, die in der Client-Konfiguration gesetzt werden kann:
ubuntu@nom-1:~$ cat /etc/nomad/client.hcl
data_dir = "/opt/nomad"
enable_syslog = true
region = "stage"
datacenter = "stage1"
client {
enabled = true
node_class = "nom-pool"
servers = ["192.168.5.164"]
server_join {
retry_join = [ "192.168.5.164" ]
retry_max = 3
retry_interval = "15s"
}
}
plugin "docker" {
}
Im Horizon erscheinen nach dem Scaling-Event dann die vom Nomad-Autoscaler erzeugten Instanzen:
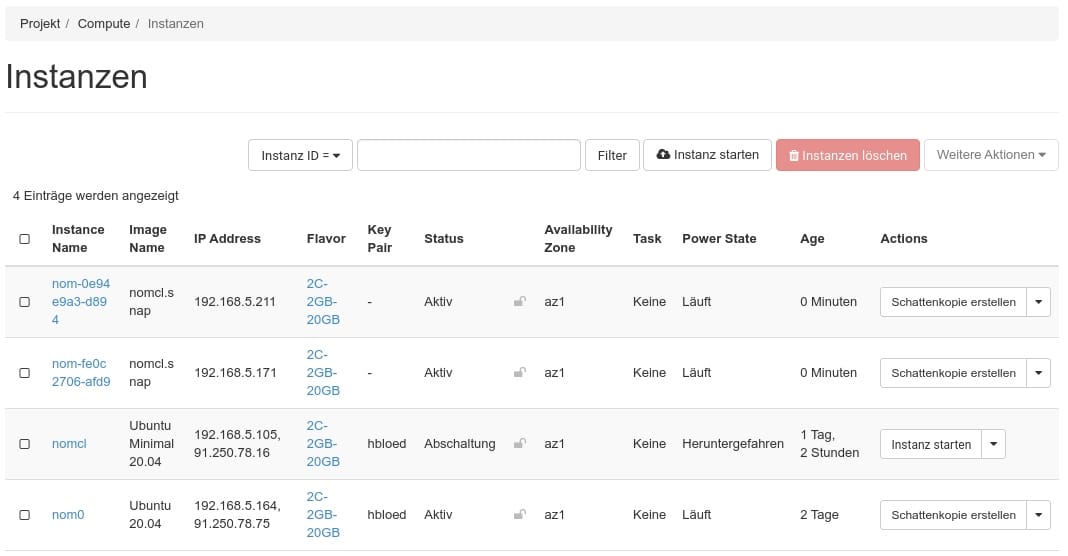
In der Nomad GUI melden dann nach kurzer Zeit die Nomad-Clients an, die sich beim Server gemeldet haben, weil das verwendete Image die oben beschriebene Clientkonfiguration benutzt:
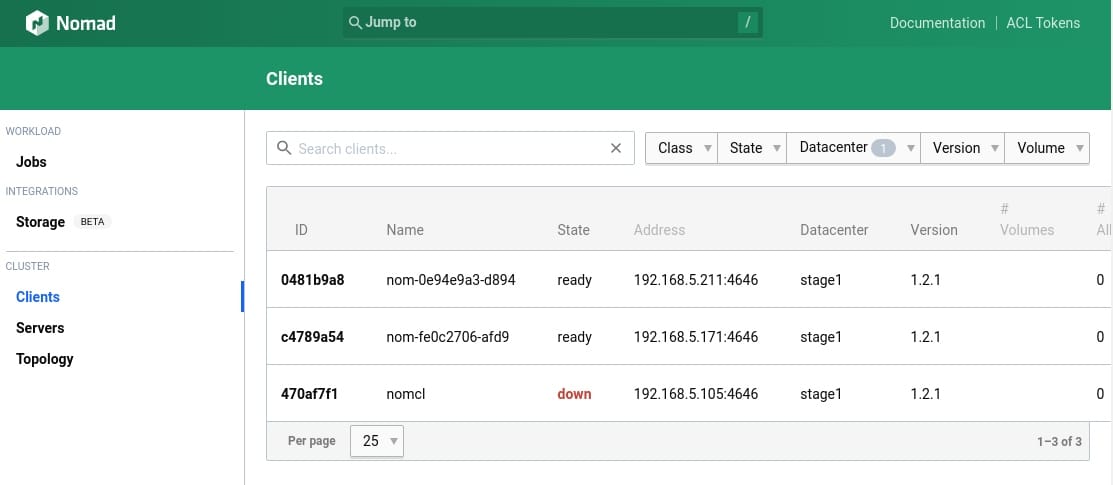
Der Nomad-Autoscaler sollte dann bis zu insgesamt vier Instanzen erzeugen, wenn auf den ersten beiden die CPU-Auslastung auf über 70% ansteigt.
Der "nomcl" Client wird zum Start für nomad-apm benötigt. Die Dokumentation zum Nomad APM Plugin sagt:
"The Nomad APM plugin should only be used when scaling based on CPU and memory usage. For more advanced scenarios, such as scaling a cluster to zero clients, you should use a different APM plugin."
Deshalb meldet der Nomad-Autoscaler nach dem Start bei der ersten Evaluation "error="failed to query source: no nodes identified within pool", sofern kein Nomad Node mit der node_class "nom-pool" gestartet ist (und macht dann offenbar auch nicht weiter, um z. B. passende Nodes zu starten). Wenn man das Nomad APM Plugin verwendet, um Metriken der verwendeten Nodes zu sammeln, gelingt das am besten, in dem man einen Grundstock an Nodes verwendet, welcher sich per Autoscaling um einen dynamisch skalierbaren Teil erweitern lässt.
Grundsätzlich ist Autoscaling aber nicht trivial. Wenn CPU- und Memory-Auslastung betrachtet werden, kann man entweder sehr niedrige Werte angeben, damit der Autoscaler dann im richtigen Moment auch schon Nodes ohne Allocations bereitgestellt hat oder man muß (vermutlich auch mit Prometheus) ermitteln, wieviele "pending" Allocations es gerade gibt (hier die entsprechenden Metriken), um dafür dann neue Nodes bereitzustellen (was natürlich deutlich mehr Zeit benötigt als auf schon bestehenden Nodes zu deployen). Bei meinen aktuellen Versuchen (mit niedrigen Schwellwerten kommt dann sowas heraus:
2021-12-08T13:00:31.983Z [INFO] policy_eval.worker: scaling target: id=d407310f-b618-5004-0aae-2232859f7909 policy_id=560ba65d-66a3-0684-d9e6-a06c05567dd6 queue=cluster target=os-nova from=2 to=7 reason="scaling up because factor is 3.314972" meta=map[nomad_policy_id:560ba65d-66a3-0684-d9e6-a06c05567dd6]
2021-12-08T13:03:46.635Z [INFO] external_plugin.os-nova: successfully performed and verified scaling out: desired_count=5 pool_name=nom-pool action=scale_out timestamp=2021-12-08T13:03:46.634Z
Die zugehörige Policy fängt so an:
scaling "worker_pool_policy" {
enabled = true
min = 2
max = 7
[...]
Ich hätte natürlich erwartet, dass schrittweise von zwei bis sieben erweitert wird - und nicht auf sieben. Jetzt hat man zwar fünf weitere Nodes ohne Allocations aber einer hätte es auch getan. Mal sehen, wie sich das ganze mit Prometheus anlässt. Denn mit dem "prometheus" APM Plugin wäre theoretisch wohl auch ein "scale to zero" möglich.
Nomad Pack
Kleiner Exkurs. Zusammen mit Nomad 1.2 wurde auch ein "technical preview" von Nomad-Pack vorgestellt. Damit kann eine Registry aus parameterisierbaren Nomad-Jobs aufgebaut werden. Hashicorp ist gleich mal mit einer Community-Registry gestartet, in der sich auch schon ein paar Packs angefunden haben. Die Benutzung ist relativ einfach. Hier ein Blick auf die Registry:
root@nom0:~# nomad-pack registry list
PACK NAME | REF | METADATA VERSION | REGISTRY | REGISTRY URL
---------------------------+--------+------------------+-----------+-----------------------------------------------------
csi_openstack_cinder | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
drone | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
faasd | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
fabio | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
grafana | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
haproxy | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
hello_world | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
influxdb | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
jenkins | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
loki | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
nginx | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
nomad_autoscaler | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
nomad_ingress_nginx | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
outline | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
prometheus | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
prometheus_node_exporter | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
prometheus_snmp_exporter | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
promtail | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
simple_service | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
tempo | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
tfc_agent | latest | 0.1.0 | default | github.com/hashicorp/nomad-pack-community-registry
traefik | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
wordpress | latest | 0.0.1 | default | github.com/hashicorp/nomad-pack-community-registry
wasmcloud | latest | 0.0.1 | wasmcloud | github.com/jordan-rash/wasmcloud-nomad-pack
Man interagiert mit den Packs genauso wie mit Job-Files, muß jedoch ggfs. Parameter übergeben. Z. B. will Promtail konfiguriert werden. Welche Parameter man einstellen kann, sieht man im entsprechenden git-Repo und in der Ausgabe:
root@nom0:~# nomad-pack info promtail
Pack Name promtail
Description Promtail is an agent which ships the contents of local logs to a private Loki instance or Grafana Cloud.
Application URL https://grafana.com/docs/promtail/latest/clients/promtail
Application Author Grafana
Pack "promtail" Variables:
- "datacenters" (list of string) - A list of datacenters in the region which are eligible for task placement.
- "config_file" (string) - Path to custom Promtail configuration file.
- "client_urls" (list of string) - A list of client url's for promtail to send it's data to.
- "container_args" (list of string) - Arguments passed to the Promtail docker container
- "extra_mounts" (list of object) - Additional mounts to create in the Promtail container
- "job_name" (string) - The name to use as the job name which overrides using the pack name.
- "journal_max_age" (string) - Maximum age of journald entries to scrape.
- "promtail_group_network" (object) - The Promtail network configuration options.
- "promtail_group_services" (list of object) - Configuration options of the promtail services and checks.
- "resources" (object) - The resource to assign to the promtail service task.
- "default_mounts" (list of object) - Mounts that are configured when using the default Promtail configuration
- "namespace" (string) - The namespace where the job should be placed.
- "region" (string) - The region where the job should be placed.
- "version_tag" (string) - The docker image version. For options, see https://hub.docker.com/grafana/promtail
- "constraints" (list of object) - Constraints to apply to the entire job.
Die Parameter, die man übergeben möchte, schreibt man einfach in eine HCL-Datei und übergibt sie dann beim Aufruf:
root@nom0:~# nomad-pack plan wordpress -f /root/wordpress-vars.hcl
+ Job: "borg"
+ Task Group: "mariadb" (1 create)
+ Task: "connect-proxy-mariadb" (forces create) + Task: "mariadb" (forces create)+ Task Group: "phpmyadmin" (1 create)
+ Task: "connect-proxy-phpmyadmin" (forces create) + Task: "phpmyadmin" (forces create)+ Task Group: "wordpress" (1 create)
+ Task: "connect-proxy-wordpress" (forces create) + Task: "wordpress" (forces create)
» Scheduler dry-run:
- All tasks successfully allocated.
Plan succeeded
Das erleichtert es natürlich sehr, Jobs in Nomad zu deployen, da man selbst keine Job-Files mehr erstellen muss. Umgekehrt erleichtert es natürlich Anbietern von Software auch deren Verteilung.