Der Artikel ist im März 2019 erschienen
Äh - mit den Kubernetes-Clustern kamen die Prometheus-Instanzen. Wir hatten es ja bei Spiegel/Tectonic schon gesehen und sehen es ja bei jedem neuen K8S-Angebot: Wir liefern bei jedem Cluster ein Prometheus auf Basis des Prometheus Operators für Monitoring, Reporting und Alerting mit. Die Prometheus Dokumentation sagt selbst, dass die lokale Datenspeicherung für lange Zeit bzw. Archivzwecke nicht empfohlen ist. Stattdessen gibt es in der Dokumentation im Bereich "Integrations" den Punkt "Remote Endpoints and Storage" der mehrere Alternativen anbietet. Bisher hatten wir mit Crate geliebäugelt - ohne das schon näher betrachtet zu haben.
Am Wochenende bin ich dann über eine Lösung gestolpert, die (komischerweise) nicht auf der genannten Seite in der Prometheus-Dokumentation gelistet ist: Thanos.
Wie war ich drauf gekommen? Joyent hatte bei den letzten Plattform-Releases von Triton bekannt gegeben, dass sdc-cloud-analytics "deprecated" ist und aufgegeben wird. Als Ersatz sollen auch bei Triton dann Prometheus und Grafana zum Einsatz kommen. Dazu gibt es im Joyent-Repo schon länger an vielen Stellen Bewegung. Bisher hatte ich nur keinen Hinweis darauf gefunden, wie Joyent das Problem der Langzeitspeicherung von Prometheus-Daten angehen wollte. Es liegt natürlich nahe, dass Joyent dafür den eigenen Object-Store verwenden möchte - aber es gab erstmal keinen Hinweis darauf, wie das bewerkstelligt werden sollte. Zufällig habe ich dann herausgefunden, dass Richard Kiene an einem Rewrite des Manta Gateway-Codes für Minio arbeitet. Nicht umsonst befinden sich auch Clones des Thanos- und des Minio-Repos in seinem github-Account, in denen man seine Änderungen schon sehen kann.
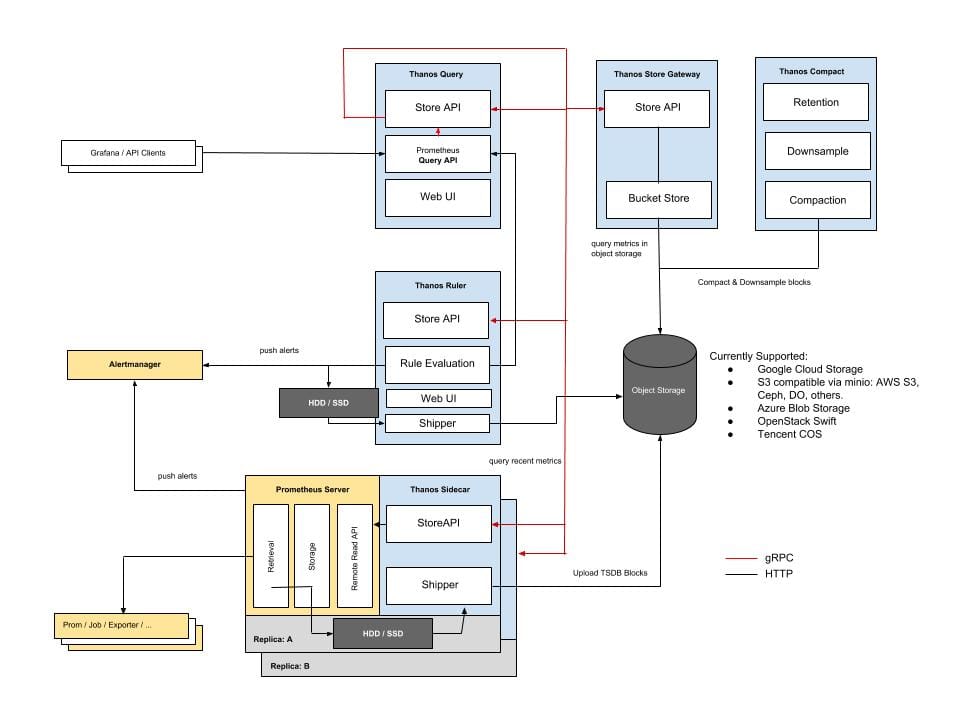
Thanos kommt als Go-Binary daher, welches mit verschiedenen Parametern aufgerufen werden kann, um die oben gezeigten Funktionen zu erfüllen:
root@1a2a951e-8638-ca36-ce93-8aeff2cf64aa:~/thanos/thanos-0.6.0.linux-amd64# ./thanos
usage: thanos [<flags>] <command> [<args> ...]
A block storage based long-term storage for Prometheus
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--version Show application version.
--log.level=info Log filtering level.
--log.format=logfmt Log format to use.
--tracing.config-file=<tracing.config-yaml-path>
Path to YAML file that contains tracing configuration.
--tracing.config=<tracing.config-yaml>
Alternative to 'tracing.config-file' flag. Tracing configuration in YAML.
Commands:
help [<command>...]
Show help.
sidecar [<flags>]
sidecar for Prometheus server
store [<flags>]
store node giving access to blocks in a bucket provider. Now supported GCS, S3, Azure, Swift and Tencent COS.
query [<flags>]
query node exposing PromQL enabled Query API with data retrieved from multiple store nodes
rule [<flags>]
ruler evaluating Prometheus rules against given Query nodes, exposing Store API and storing old blocks in bucket
compact [<flags>]
continuously compacts blocks in an object store bucket
bucket verify [<flags>]
Verify all blocks in the bucket against specified issues
bucket ls [<flags>]
List all blocks in the bucket
bucket inspect [<flags>]
Inspect all blocks in the bucket in detailed, table-like way
bucket web [<flags>]
Web interface for remote storage bucket
downsample [<flags>]
continuously downsamples blocks in an object store bucket
receive [<flags>]
Accept Prometheus remote write API requests and write to local tsdb (EXPERIMENTAL, this may change drastically without notice)
check rules <rule-files>...
Check if the rule files are valid or not.
Im Getting-Started Dokument werden die ersten Schritte erklärt. Thanos in seiner Funktion als "Sidecar" für Prometheus benötigt als Parameter wenigstens den Pfad zum Prometheus Storageverzeichnis, die Prometheus-URL und eine Konfigurationsdatei für ein Object-Storage, welches Thanos verwenden kann. Die ersten beiden Parameter sind klar. Für den Object-Store verwende ich Minio als Frontend zu Manta:
type: S3
config:
bucket: "thanos"
endpoint: "10.65.69.20"
region: ""
access_key: "mhbloed"
insecure: true
signature_version2: true
encrypt_sse: false
secret_key: "f5:3c:8a:51:2c:c1:24:66:82:0d:4c:10:e6:d7:92:79"
put_user_metadata: {}
http_config:
idle_conn_timeout: 0s
response_header_timeout: 0s
insecure_skip_verify: true
trace:
enable: true
part_size: 0
Das Minio-Gateway habe ich auf der angegebenen IP-Adresse gestartet. Hier sind alle Verschlüsselungsparameter auf "unsicher" gestellt. Der Start von thanos sieht dann ungefähr so aus:
root@1a2a951e-8638-ca36-ce93-8aeff2cf64aa:~/thanos/thanos-0.6.0.linux-amd64# ./thanos sidecar --tsdb.path /root/prom/prometheus-2.11.1.linux-amd64/data --prometheus.url "http://10.65.69.18:9090" --objstore.config-file bucket_config.yml
level=info ts=2019-08-02T09:45:12.527898802Z caller=main.go:154 msg="Tracing will be disabled"
level=info ts=2019-08-02T09:45:12.528492089Z caller=main.go:274 component=sidecar msg="disabled TLS, key and cert must be set to enable"
level=info ts=2019-08-02T09:45:12.528560883Z caller=factory.go:39 msg="loading bucket configuration"
level=info ts=2019-08-02T09:45:12.529472603Z caller=sidecar.go:289 msg="starting sidecar"
level=info ts=2019-08-02T09:45:12.529574807Z caller=sidecar.go:222 component=sidecar msg="Listening for StoreAPI gRPC" address=0.0.0.0:10901
level=info ts=2019-08-02T09:45:12.529982554Z caller=main.go:326 msg="Listening for metrics" address=0.0.0.0:10902
level=info ts=2019-08-02T09:45:12.530413146Z caller=reloader.go:154 component=reloader msg="started watching config file and non-recursively rule dirs for changes" cfg= out= dirs=
level=info ts=2019-08-02T09:45:12.536582086Z caller=sidecar.go:154 msg="successfully loaded prometheus external labels" external_labels="{cluster=\"de-gt-2\"}"
level=info ts=2019-08-02T09:45:14.782337757Z caller=shipper.go:349 msg="upload new block" id=01DH8J1KFMA6BCV3PBAJ0FT0Q3
level=info ts=2019-08-02T09:46:04.114769517Z caller=shipper.go:349 msg="upload new block" id=01DH8RXAP2ZC71122KZJKFQ2RW
Vorher musste allerdings die Prometheus-Konfiguration noch angepasst werden. Zunächst benötigt Prometheus einen Eintrag für external_labels. Vermutlich um mehrere Prometheus-Instanzen daran unterscheiden zu können:
global:
scrape_interval: 10s
evaluation_interval: 8s
# scrape_timeout is set to the global default 10s
external_labels:
cluster: de-gt-2
scrape_configs:
- job_name: triton-lab
scheme: https
tls_config:
cert_file: /root/.triton/docker/hbloed@cloudapi_de-gt-2_cns_tgos_de/cert.pem
key_file: /root/.triton/docker/hbloed@cloudapi_de-gt-2_cns_tgos_de/key.pem
insecure_skip_verify: true
triton_sd_configs:
- account: 'hbloed'
dns_suffix: 'cmon.de-gt-2.cns.tgos.de'
endpoint: 'cmon.de-gt-2.cns.tgos.de'
version: 1
tls_config:
cert_file: /root/.triton/docker/hbloed@cloudapi_de-gt-2_cns_tgos_de/cert.pem
key_file: /root/.triton/docker/hbloed@cloudapi_de-gt-2_cns_tgos_de/key.pem
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_triton_machine_alias]
target_label: instance
Und dann muss Prometheus mit den Parametern --storage.tsdb.min-block-duration=2h --storage.tsdb.max-block-duration=2h aufgerufen werden - was ich hätte wissen können, wenn ich die Dokumentation zur Sidecar-Komponente gelesen hätte. In dem man Min- und Max-Parameter auf denselben Wert setzt, unterbindet man die von Prometheus selbst durchgeführte Verdichtung der Werte. Diese würde zu defekten Daten führen, wenn danach auch noch Thanos seine Verdichtung durchführt:
"If you choose to use the sidecar to also upload to object storage:
- The
--storage.tsdb.min-block-durationand--storage.tsdb.max-block-durationmust be set to equal values to disable local compaction on order to use Thanos sidecar upload, otherwise leave local compaction on if sidecar just exposes StoreAPI and your retention is normal. The default of2his recommended. Mentioned parameters set to equal values disable the internal Prometheus compaction, which is needed to avoid the uploaded data corruption when Thanos compactor does its job, this is critical for data consistency and should not be ignored if you plan to use Thanos compactor. Even though you set mentioned parameters equal, you might observe Prometheus internal metricprometheus_tsdb_compactions_totalbeing incremented, don't be confused by that: Prometheus writes initial head block to filesytem via internal compaction mechanism, but if you have followed recommendations - data won't be modified by Prometheus before sidecar uploads it. Thanos sidecar will also check sanity of the flags set to Prometheus on the startup and log errors or warning if they have been configured improperly (#838). - The retention is recommended to not be lower than three times the min block duration, so 6 hours. This achieves resilience in the face of connectivity issues to the object storage since all local data will remain available within the Thanos cluster. If connectivity gets restored the backlog of blocks gets uploaded to the object storage."
Das Ganze funktioniert zunächst also relativ einfach - ohne große Eingriffe in die bestehende Prometheus-Konfiguration. Wenn diese schon den Vorgaben von Thanos entspricht, ist nichteinmal ein Neustart von Prometheus erforderlich.
Praktischerweise versucht Thanos den Upload der Chunks in den Objectstore so lange, bis es auch geklappt hat. Falls die Netzwerkverbindung oder das Storage mal unpässlich ist, ist das also erstmal kein Beinbruch. Im Datenverzeichnis von Prometheus legt Thanos ein Verzeichnis für die hochzuladenen Blocks an und führt in der Datei thanos.shipper.json Buch über die bereits hochgeladenen Chunks. Wenn Uploads ausstehen, liegen diese in
root@1a2a951e-8638-ca36-ce93-8aeff2cf64aa:~/prom/prometheus-2.11.1.linux-amd64/data/thanos/upload# ls -la
total 2
drwxr-xr-x 3 root root 3 Aug 5 11:03 .
drwxr-xr-x 3 root root 3 Aug 2 06:29 ..
drwxr-xr-x 3 root root 5 Aug 5 11:03 01DHGPZ72TRG99SQGE4VT8B7B3
und obwohl sie in der Datei thanos.shipper.json schon aufgeführt sind:
{
"version": 1,
"uploaded": [
"01DH84A52V2TY23ESDKJJES8KK",
"01DH8B5W909CSPXJDRRTFWHKS6",
"01DH8J1KFMA6BCV3PBAJ0FT0Q3",
"01DH8RXAP2ZC71122KZJKFQ2RW",
"01DH8ZS1XMP8J609Z47Z5X1YR7",
"01DH96MSKREJ3EMM07D12SCYQA",
"01DH9DGGTCPQK64ZJM6MCGSDN8",
"01DH9MC80EMX5SSEDZ04J7GERJ",
"01DH9V7YZFZ4QHWMK7WJT9G9B3",
]
}
Nachdem die Komponente "Sidecar" eingerichtet ist, kann man sich z. B. der Komponente "Query" zuwenden. Der Aufruf sieht z. B. so aus:
root@711b7895-00e6-ce0c-a9c4-f279d9c25325:/mnt/data/thanos/thanos-0.6.0.linux-amd64# ./thanos query --http-address 0.0.0.0:19191 --store 10.65.69.18:10901
level=info ts=2019-08-05T11:44:23.959562868Z caller=main.go:154 msg="Tracing will be disabled"
level=info ts=2019-08-05T11:44:23.961727253Z caller=main.go:274 component=query msg="disabled TLS,
key and cert must be set to enable"
level=info ts=2019-08-05T11:44:23.962090411Z caller=query.go:457 msg="starting query node"
level=info ts=2019-08-05T11:44:23.962719165Z caller=query.go:427 msg="Listening for query and metrics" address=0.0.0.0:19191
level=info ts=2019-08-05T11:44:23.963085735Z caller=query.go:450 component=query msg="Listening for StoreAPI gRPC" address=0.0.0.0:10901
level=info ts=2019-08-05T11:44:28.97059554Z caller=storeset.go:263 component=storeset msg="adding new store to query storeset" address=10.65.69.18:10901
Sind mehrere Stores vorhanden, können diese parallel hinzugefügt werden. Die Query-Dokumentation enthält ein paar Beispiele dazu. Dabei kann Query die Inhalte der verschiedenen Stores deduplizieren. Duplikate können in einem HA-Setup mit Prometheus nicht verhindert werden - um so sinnvoller ist diese Funktion. Thanos-Query präsentiert dabei eine ähnliche GUI wie Prometheus
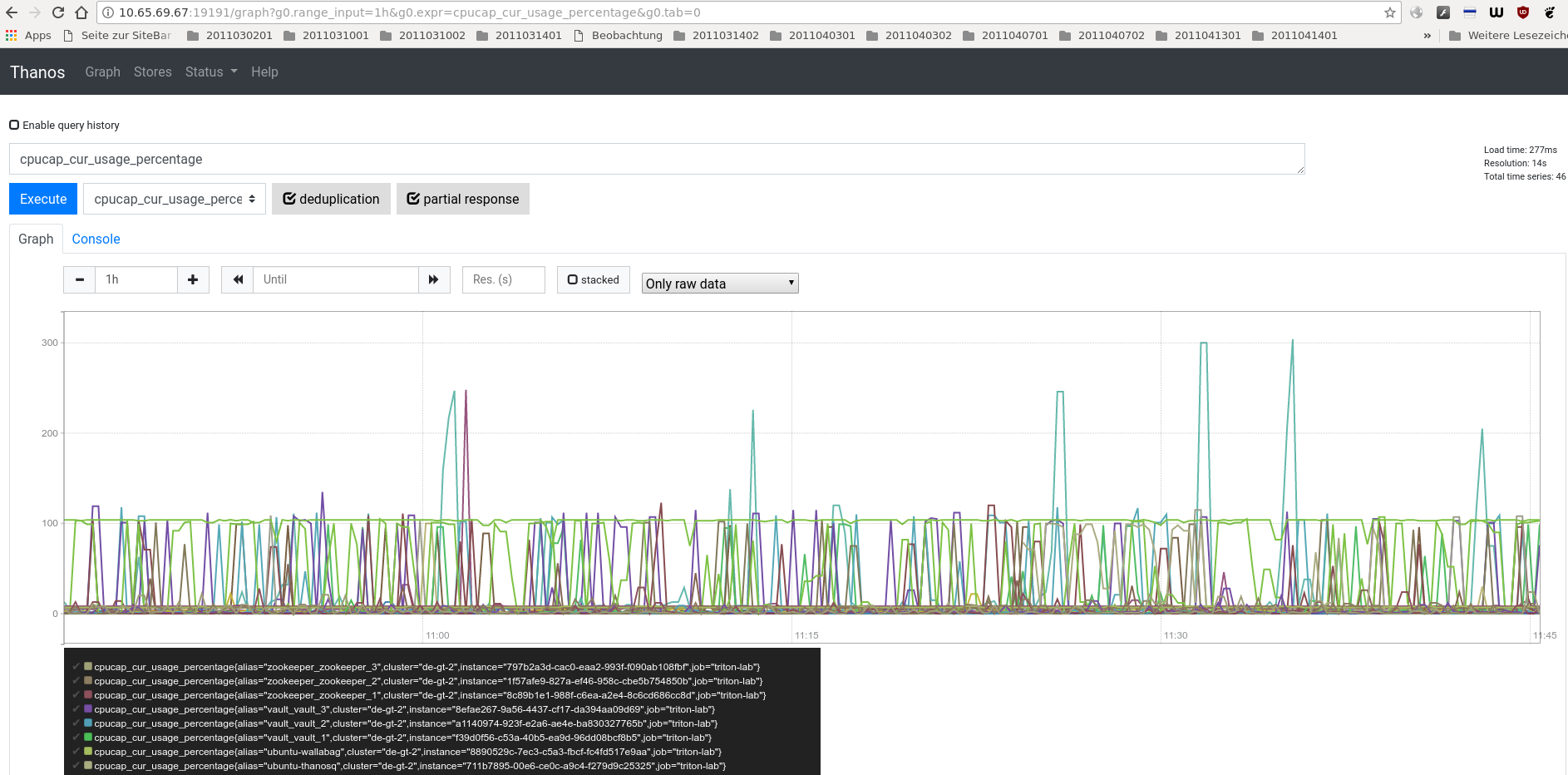
unterscheidet sich jedoch auf den zweiten Blick deutlich. Unter "Status" wird z. B. nur der Status der angeschlossenen Object-Stores angezeigt:

Weiterhin fallen die schon in der Dokumentation erwähnten Funktionen auf. Query kann/sollte in einen HA-Prometheus Setup als Quelle für Grafana verwendet werden. Innerhalb von Grafana wählt man dafür einfach die Prometheus-Datenquelle da Prometheus und Thanos protokollkompatibel sind. Laut Dokumentation ist Query komplett stateless und deshalb problemlos horizontal skalierbar. Mit den bisher betrachteten Funktionen lassen sich also mindestens folgende Dinge bewerkstelligen:
- Entkopplung von Scraping und Abfragen zur Entlastung von Prometheus: Mit Thanos Sidecar kann Prometheus seine Zeit mit Scraping verbringen während z. B. Thanos Query Anfragen entgegen nimmt.
- Langzeitstorage für Prometheus: Die lokale Prometheus-Instanz braucht nur wenige Metriken zu speichern während ein Object-Store die Langzeitspeicherung übernimmt.
- Optimierung von Queries gegen Prometheus: Durch die Verlagerung auf Object-Stores und die horizontale Skalierung von Thanos-Query sollten sich auch komplexe Anfragen beschleunigen lassen.
- Deduplizierung im Prometheus HA-Setup: Thanos-Query kann auch doppelt gespeicherte Metriken, die in Prometheus HA-Setups auftreten, erkennen und in Abfragen deduplizieren.
Dabei bietet sich der Einsatz im Container an, da die verschiedenen Thanos-Komponenten keinen oder kaum State halten und deshalb auch nach Neustarts schnell wieder zur Verfügung stehen. Durch die Aufteilung in verschiedene Komponenten kann man einerseits sehr einfach Teile des Setups horizontal skalieren (es muss kein State repliziert werden) und andererseits braucht man nur die Komponenten einzusetzen, die für die eigene Lösung gerade benötigt werden.
Inzwischen ist komischerweise mit Cortex ein Projekt aufgetaucht welches fast identische Funktionen wie Thanos bieten soll. Die Architektur wirkt jedoch deutlich komplexer
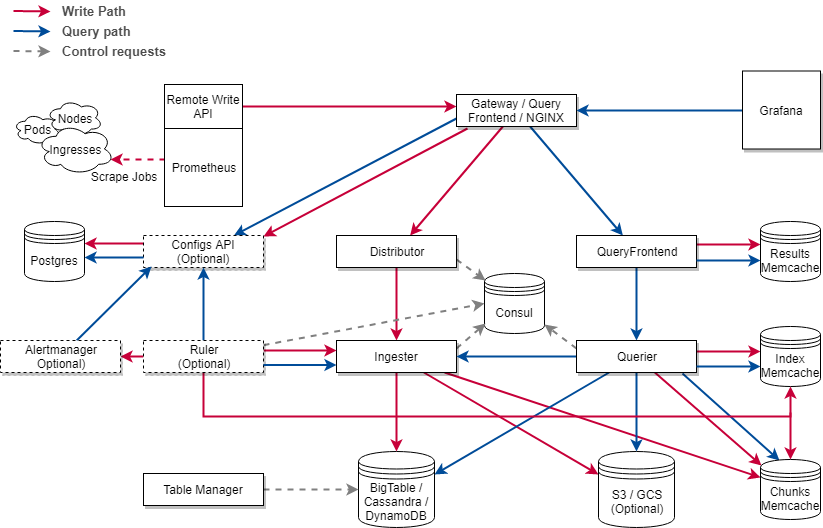
Sowohl Thanos als auch Cortex sind als Projekte in der CNCF Sandbox angenommen worden. Im Moment würde ich Thanos den Vorzug geben.
Links:
RFD 150 Operationalizing Prometheus, Thanos, and Grafana
Thanos: Global, durable Prometheus monitoring
Introducing Thanos: Prometheus at scale
Making Prometheus more awesome with Thanos
PromCon 2018: Thanos - Prometheus at Scale
Thanos - a Scalable Prometheus with Unlimited Storage
Warum es parallel noch ein Projekt Cortex gibt (Cortex: a multi-tenant, horizontally scalable Prometheus-as-a-Service) und wie es sich von Thanos unterscheidet, ist mir noch nicht ganz klar.
Running Thanos without Kubernetes
Thanos and the Prometheus Operator
HA + Scalable Prometheus with Thanos
HA Prometheus – The Thanos Evolution
How to integrate thanos in existing prometheus setup
Beim letzten PromCon EU (2019) gab es ein paar interessante Talks zu Thanos und Cortex:
Interessant sind die Möglichkeiten, wo Thanos und Cortex heute schon integriert werden können (für Caching und das Schreiben auf Object Stores).