Da ich gerade kurz Zeit habe, ein paar Nomad-Szenarios zu testen, schreibe ich die Erkenntnisse hier kurz auf.
Ich hatte gelesen, dass REWE in jeder Filiale einen eigenen Kubernetes-Cluster betreibt - 7000 Cluster an der Zahl. Da hatte ich mir natürlich überlegt, ob ich das Problem auch so gelöst hätte. Dabei war mir dann wieder das Tutorial "Schedule edge Services with native service discovery" für Hashicorp Nomad eingefallen, in welchem es quasi eine "globale" Management Plane (den Nomad Server Cluster) und "Edge Locations" gibt, in denen einfach einzelne Nomad Clients stehen. Für 7000 Filialen wäre möglicherweise ein Setup mit ein paar regionalen Clustern sinnvoll - insbesondere, weil Nomad auch darauf mit multi-region deployments vorbereitet ist. Auch das Nomad für Linux auf amd64 und arm64 Architektur sowie für Windows (amd64) verfügbar ist, scheint einem solchen Szenario entgegen zu kommen (im oben verlinkten Artikel wird erwähnt, dass auf Windows Clients Kubernetes im Windows-Subsystem für Linux (WSL) läuft).
Also schnell einen Nomad Cluster ohne Consul aufgesetzt und dann ein paar "remote" Clients eingebunden. Da ich gerade eine RL300 von HPE zum Testen da hatte, konnte ich auch gleich ausprobieren, wie sich Multi-Plattform Docker-Images verwenden (völlig transparent).
Die RL300 war "von außen" (also auch nicht vom Nomad Cluster) nicht erreichbar, konnte aber natürlich "nach draussen" kommunizieren. Ich war überrascht, dass sich die Maschine einfach im Cluster registrieren konnte. Ich musste nur die Public-IP, die die Maschine bei ausgehenden Verbindungen zugewiesen bekommt per advertise in der Client-Konfigurationsdatei angeben:
advertise {
# Defaults to the first private IP address.
http = "my.pub.lic.ip" # must be reachable by Nomad CLI clients
rpc = "my.pub.lic.ip" # must be reachable by Nomad client nodes
serf = "my.pub.lic.ip" # must be reachable by Nomad server nodes
}
Offenbar baut der Client zum Server eine TCP-Verbindung auf, die dann in beide Richtungen benutzt werden kann.
Danach war es simpel mit nomad job init die Beispiel Job-Datei zu generieren und Redis auzurollen. Mit spread kann man leicht zwei Instanzen auf die Datacenter verteilen:

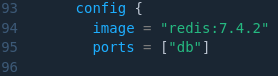
In der Image-Definition für Docker brauchen die verschiedenen CPU-Architekturen nicht berücksichtigt zu werden:
Für Kubernetes ist so ein Setup mit "remote control plane" offenbar nicht zu empfehlen.