In Postgres Cluster ohne LB aber mit Patroni habe ich Patroni von Hand in drei VMs aufgesetzt, um mich etwas mit der Software vertraut zu machen. In Patroni Cluster im Container habe ich ein Patroni Cluster automatisiert (mit Packer und Terraform) in SmartOS Containern aufgesetzt, um einerseits möglichst hohe Performance durch das Deployment in Containern auf Bare-Metal und auf der anderen Seite Multi-Mandantenfähigkeit durch das Deployment in SmartOS Containern zu erreichen.
Jetzt soll das Patroni Cluster in Linux Containern (auf Basis von Docker) in VMs ausgerollt werden. Das Setup könnte aber unverändert auch auf dediziert genutzten Bare-Metal Hosts ausgerollt werden, wenn die Leistung in Docker Containern innerhalb von VMs nicht ausreicht.
Da Patroni auch weiterhin ein "dcs" benötigt, um die anderen Instanzen im Cluster zu finden, ist Consul auch Teil diesen Setups. Für Testzwecke habe ich in der pluscloud open eine VM ausgerollt, auf der ich die Komponenten
- Nomad
- Nomad-Autoscaler
- Consul
installiert habe. Diese VM dient als Server-Instanz. In einer Produktionsumgebung würde man mindestens drei davon benötigen, um wenigstens einen VM-Ausfall überstehen zu können, ohne daß der gesamte Service ausfällt. Die Konfiguration ist übersichtlich:
Nomad-Server (gestartet mit nomad agent --config=/etc/nomad -bind=0.0.0.0 -dev):
root@nom0:/etc/nomad# cat server.hcl
data_dir = "/opt/nomad"
enable_syslog = true
region = "stage"
datacenter = "stage1"
server {
enabled = true
bootstrap_expect = 1
server_join {
retry_join = [ "192.168.5.164" ]
retry_interval = "15s"
}
}
consul {
server_service_name = "nomad"
}
Consul-Server (gestartet mit consul agent -config-dir=/etc/consul):
root@nom0:/etc/consul# cat server.hcl
#
datacenter = "stage1"
data_dir = "/opt/consul"
bind_addr = "192.168.5.164"
client_addr = "0.0.0.0"
bootstrap_expect = 1
ui = true
server = true
retry_join = ["192.168.5.164"]
recursors = ["8.8.8.8", "8.8.4.4"]
connect {
enabled = true
}
dns_config {
service_ttl {
"*" = "5s"
}
}
Zusätzlich habe ich mir ein Image für meine "Worker-Nodes" gebaut, welches der Nomad-Autoscaler zum instanziieren benutzt. In dem Image sind auch nur Nomad und Consul (allerdings mit einer Client-Konfiguration) installiert, die vom systemd beim Start der Instanz gestartet werden.
Nomad-Client (gestartet mit /usr/local/bin/nomad agent -config /etc/nomad):
ubuntu@nom-49f01f5e-8a30:/etc/nomad$ cat client.hcl
data_dir = "/opt/nomad"
enable_syslog = true
region = "stage"
datacenter = "stage1"
client {
enabled = true
node_class = "nom-pool"
cni_path = "/opt/cni/bin"
servers = ["192.168.5.164"]
server_join {
retry_join = [ "192.168.5.164" ]
retry_max = 3
retry_interval = "15s"
}
plugin "docker" {
config {
volumes {
enabled = true
}
}
}
Consul-Client (gestartet mit /usr/local/bin/consul agent -config-dir=/etc/consul):
ubuntu@nom-49f01f5e-8a30:/etc/consul$ cat client.hcl
#
datacenter = "stage1"
data_dir = "/opt/consul"
#bind_addr = "{{ GetInterfaceIP \"ens3\" }}"
bind_addr = "0.0.0.0"
client_addr = "0.0.0.0"
retry_join = ["192.168.5.164"]
recursors = ["8.8.8.8", "8.8.4.4"]
ports {
grpc = 8502
}
connect {
enabled = true
}
dns_config {
service_ttl {
"*" = "5s"
}
}
Der "retry_join" Eintrag sorgt dafür, dass sich die Worker nach dem Start automatisch beim jeweiligen Server anmelden und für das Ausführen von Nomad-Jobs zur Verfügung stehen. Im Nomad sieht das so aus:
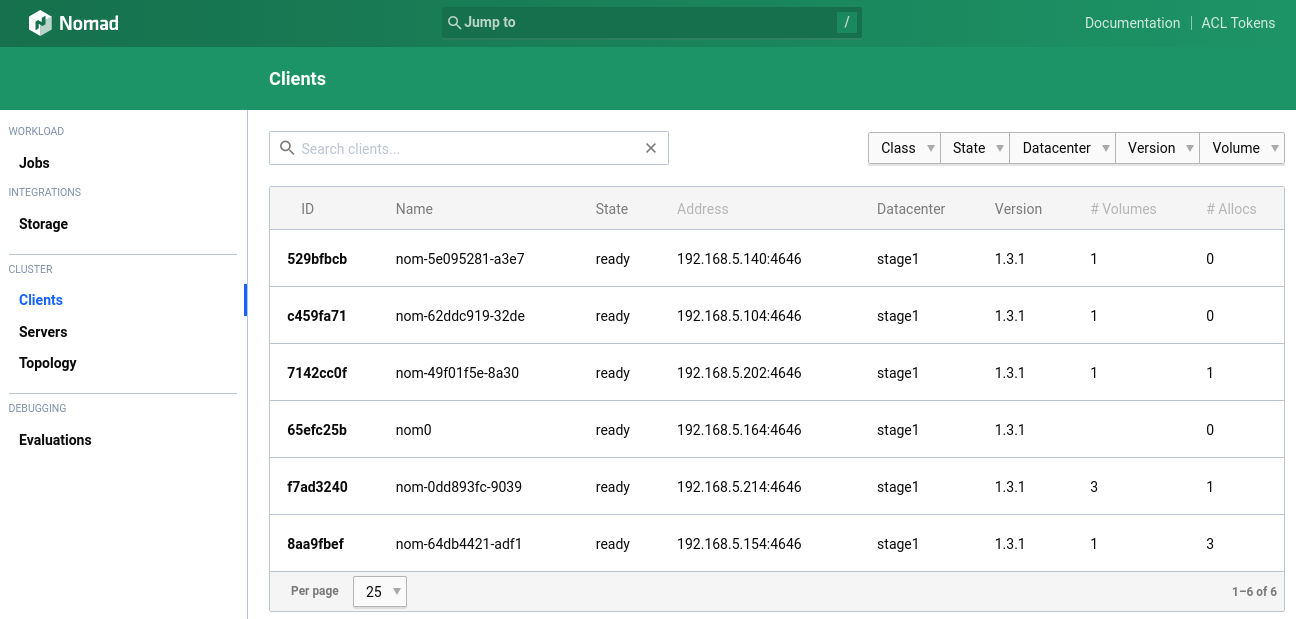
Im Consul so:
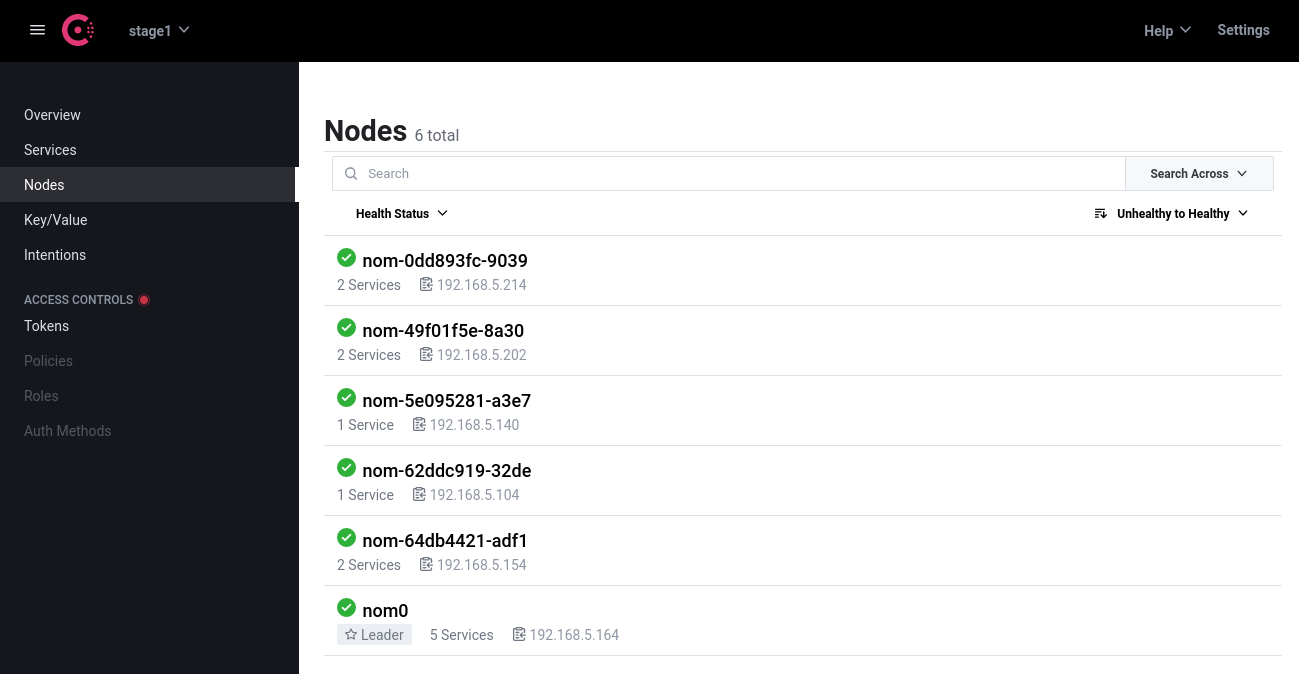
Für das Deployment eines Patroni-Clusters wird also "nur noch" ein entsprechender Nomad-Job benötigt. Zum Glück hat auch hier jemand im Netz schon Vorarbeit geleistet: nomad-pgsql-patroni.
Leider ist die Vorarbeit aber unvollständig. Sie mag funktionieren, wenn das "Cluster" nur auf einem Node laufen soll. Zusätzlich hat auch das "docker-initdb.sh"-Skript, welches der Autor verwendet, um die eingebauten Postgres-Erweiterungen PostGIS, pg_cron, pgRouting, postgres-json-schema und vector zu initialisieren, einen Bug, der dazu führt, dass sich das Cluster nicht aufbauen kann. Deshalb mußte der im Repo skizzierte Nomad-Job ein wenig umgeschrieben werden - genauso wie die Patroni-Konfiguration.
Nomad-Job für Patroni (patroni-job.hcl):
job "postgres-14-2" {
type = "service"
datacenters = ["stage1"]
group "group" {
count = 1
network {
port api { static = 8008 }
port pg { static = 5432 }
}
task "db" {
driver = "docker"
template {
data = <<EOL
scope: postgres
name: pg-{{env "node.unique.name"}}
namespace: /nomad/
restapi:
listen: 0.0.0.0:{{env "NOMAD_PORT_api"}}
connect_address: {{env "NOMAD_ADDR_api"}}
consul:
scheme: http
host: {{ env "attr.unique.network.ip-address"}}
url: http://{{ env "attr.unique.network.ip-address"}}:8500
register_service: true
bootstrap:
dcs:
postgresql:
use_pg_rewind: true
# use_slots: true
parameters:
timezone: 'UTC'
max_connections: 100
shared_preload_libraries: pg_stat_statements
shared_buffers: 64MB
work_mem: 16MB
effective_cache_size: 512MB
tcp_keepalives_idle: 300
timescaledb.telemetry_level: off
# method: local
# local:
# command: /usr/local/bin/docker-initdb.sh
# keep_existing_recovery_conf: True
initdb:
- encoding: UTF8
- data-checksums
pg_hba:
- host all postgres all md5
- host replication repl all md5
- host all all all md5
users:
postgres:
password: postgres
options:
- createrole
- createdb
repl:
password: repl
options:
- replication
postgresql:
listen: 0.0.0.0:{{env "NOMAD_PORT_pg"}}
connect_address: {{env "NOMAD_ADDR_pg"}}
# use_unix_socket: true
data_dir: /alloc/data
authentication:
replication:
username: repl
password: repl
superuser:
username: postgres
password: postgres
EOL
destination = "/secrets/patroni.yml"
}
config {
image = "ccakes/nomad-pgsql-patroni:14.1-2.tsdb_gis"
ports = ["api", "pg"]
}
resources {
memory = 1024
}
}
}
}
Für ein leichteres Verständnis des Jobs, habe ich zwei Videos verlinkt. Das eine erläutert die vier "Nomad Networking Patterns" (da wir hier Applikationen über Node-Grenzen hinweg kommunizieren lassen wollen, müssen wir hier das zweite wählen umd mit Service-Discovery arbeiten. Consul wird ja sowieso benötigt). Das andere Video zeigt, wie man aus Docker-Compose- und Kubernetes-Konfigurationen Nomad-Job-Konfigurationen erstellen kann. Dabei wird auch die Struktur von Nomad-Job-Konfigurationen erläutert.
Das obige Job-File ist eigentlich recht übersichtlich, wenn man sich das eingebaute Template für die patroni.yml mal wegdenkt. Es ist eine philosophische Frage, ob man solche Templates im eigentlichen Job-File mitführt oder ob man sie separat hält. Ich habe mich hier dafür entschieden, das Template mitzuführen.
Die Variablen im Template werden aus dem Nomad Runtime Environment und verschiedenen Node Variablen gefüttert. Im zweiten Video in den Links wird auch Go Template Syntax verwendet z. B.:
exporters:
otlp:
endpoint: "{{with nomadService "grpc.otel-collector"}}{{with index . 0}}{{.Address}}:{{.Port}}{{end}}{{end}}"
Hier wird ein IP-Adress:Port Tupel aus der neuen Nomad Service Registry abgerufen. Neben dem obigen Tutorial kann auch sockaddr (Teil von go-sockaddr) dabei helfen, das richtige Template zu erzeugen.
Um jetzt ein Patroni-Cluster auszurollen, wird der obige Job mit nomad job run patroni.hcl gestartet. Oder besser mit nomad job plan patroni.hcl zunächst geplant (ähnlich wie bei Terraform):
root@nom0:~/nomad-jobs# nomad job plan patroni.hcl
+/- Job: "postgres-14-2"
+/- Task Group: "group" (2 destroy, 1 in-place update)
+/- Count: "3" => "1" (forces destroy)
Task: "db"
Scheduler dry-run:
- All tasks successfully allocated.
Job Modify Index: 103209
To submit the job with version verification run:
nomad job run -check-index 103209 patroni.hcl
When running the job with the check-index flag, the job will only be run if the job modify index given matches the server-side version. If the index has changed, another user has modified the job and the plan's results are potentially invalid.
In diesem Fall würden zwei Instanzen zerstört, weil im Job-File "count=1" steht und ich vorher schon mit nomad job scale postgres-14-2 group 2 auf drei Instanzen skaliert hatte. Dank des Nomad Autoscalers brauchte ich mich übrigens nicht daraum zu kümmern, händisch neue Worker-Nodes zu starten. Das hat der Autoscaler automatisch gemacht.
Da ich im Job-File ein statisches Port-Mapping verwendet habe (was man tunlichst vermeiden sollte), sucht Nomad sich einen Node, auf dem diese Ports noch frei sind, lädt das Container-Image auf diesem Node herunter und startet dann mit Hilfe von Docker den Container. Das darin gestartete Patroni erkennt (mit Hilfe von Consul), dass es bereits einen Postgres-Leader gibt, lädt von diesem die aktuellen WAL-Files und startet damit eine Postgres-Replica:
root@nom-49f01f5e-8a30:~# docker exec -it 64fe69b0ed97 /usr/local/bin/patronictl -c /secrets/patroni.yml list
+----------------------+---------------+---------+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+ Cluster: postgres (7125422037505949720) -------+---------+----+-----------+
| pg-nom-0dd893fc-9039 | 192.168.5.214 | Replica | running | 1 | 15 |
| pg-nom-49f01f5e-8a30 | 192.168.5.202 | Replica | running | 1 | 0 |
| pg-nom-64db4421-adf1 | 192.168.5.154 | Leader | running | 1 | |
+----------------------+---------------+---------+---------+----+-----------+
Im Consul sind von Patroni die Cluster-Daten im Key-Value Store gespeichert worden:
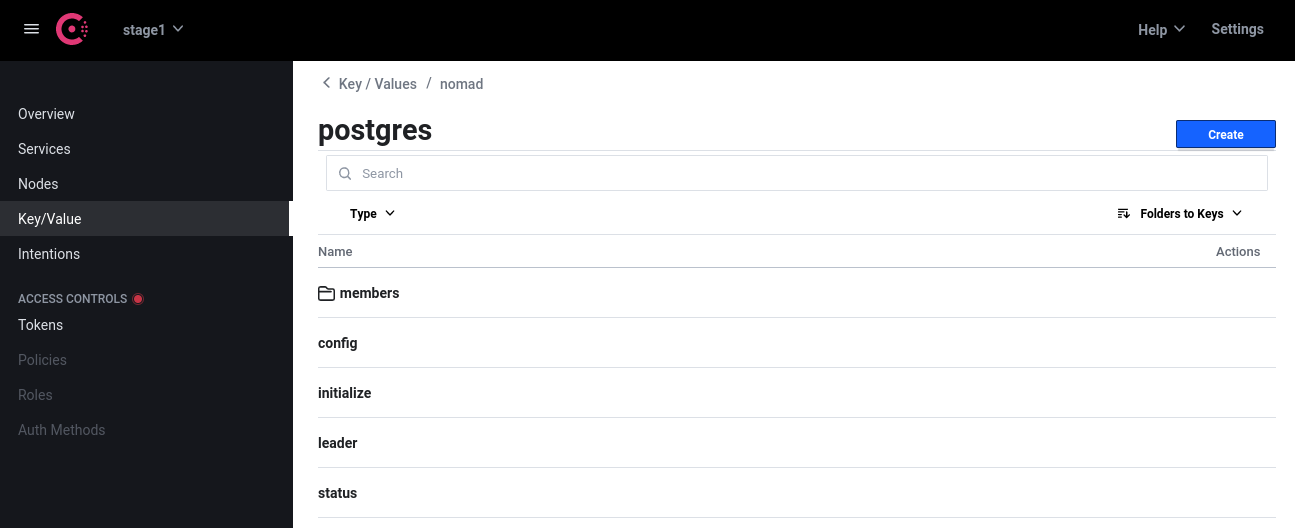
Im zweiten Video (unter den Links) wird erklärt, dass jede Nomad-Allocation (also die Instanz eines Nomad-Jobs auf einem Node) ein eigenes Verzeichnis auf dem Node (welches sich im Datenverzeichnis befindet - bei mir also /opt/nomad) hat. Hier liegen z. B. die Logfiles und die Secrets, die während des Deployments entstehen. Aber auch die Applikationsdaten. So legt Patroni hier die Postgres-Datenbank an. Beim ersten Knoten funktioniert das auch problemlos. Bei den Replica-Knoten wird das Verzeichnis leider nicht mit den richtigen Rechten angelegt und deshalb beschwert sich Postgres, dass die Verzeichnisrechte nicht stimmen und legt sich wieder hin (Postgres ist da sehr eigen). Wenn man die Rechte per Hand anpasst, startet Postgres problemlos. Es wäre also noch zu ermitteln, wie hier die Verzeichnisrechte korrekt gesetzt werden können.