Dieser Beitrag ist im August 2018 erschienen
Ich muss ja zugeben, dass mich das Thema Java in Containern ein wenig angefixt hat. Deswegen habe ich mir den Artikel Fire Up Your Data Processing with Apache Spark on vSphere Integrated Containers natürlich gleich auf Wiedervorlage gelegt. Da wir keine Installation von VIC haben, habe ich das natürlich für Triton adaptiert.
version: '2.0'
services:
master:
image: arslanabbasi/spark-master:2.2
environment:
_JAVA_OPTIONS: "-Djava.net.preferIPv4Stack=true"
SPARK_MASTER_HOST: apachesparkvmware-master-1.inst.a5ba23f5-8237-6879-e7e1-ea6f574fbde9.de-gt-2.cns.tgos.de
SPARK_MASTER_PORT: 7077
SPARK_MASTER_WEBUI_PORT: 8080
ports:
- 8080
- 7077
network_mode: bridge
worker:
image: arslanabbasi/spark-slave:2.2
environment:
_JAVA_OPTIONS: "-Djava.net.preferIPv4Stack=true"
MASTER_CTR: apachesparkvmware-master-1.inst.a5ba23f5-8237-6879-e7e1-ea6f574fbde9.de-gt-2.cns.tgos.de
MASTER_PORT: 7077
SPARK_WORKER_WEBUI_PORT: 8081
network_mode: bridge
depends_on:
- master
Ähnlich wie VIC implemeniert Triton nur ein Subset der Docker-Kommandos. Deswegen der Eintrag "network_mode: bridge". Auch scheint VIC einen eigenen Mechanismus zu haben, innerhalb des Virtual Docker Hosts (VDH) Namen bereitzustellen. Triton verwendet ganz normal DNS, welches über den Container Name Service (CNS) dynamisch konfiguriert wird. Deshalb konnte ich den Namen des Spark Master Servers fest eintragen, da dieser im DNS eindeutig ist.
Das war schon alles, was notwendig war, um die beiden Instanzen mit docker-compose hochfahren und die Zahl der Worker mit "docker-compose scale worker=5" auf fünf erhöhen zu können. Spark stellt offenbar eine einfache GUI zur Verfügung. Die sieht ungefähr so aus:
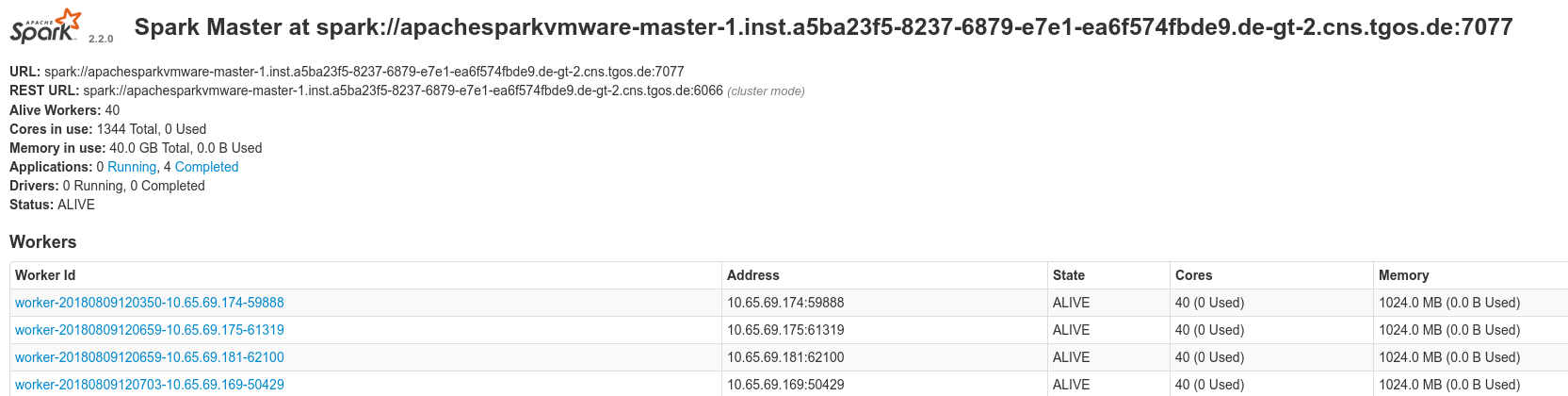
Netterweise wird im Artikel auch gleich eine Anwendung mitgeliefert: Das verteilte Schätzen der Zahl Pi:
docker run --rm p7hb/docker-spark /usr/local/spark-2.2.0-bin-hadoop2.7/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://10.65.69.168:7077 /usr/local/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 100
Und hier sieht man meine Versuche mit 5, 10, 20 und 40 Workern:
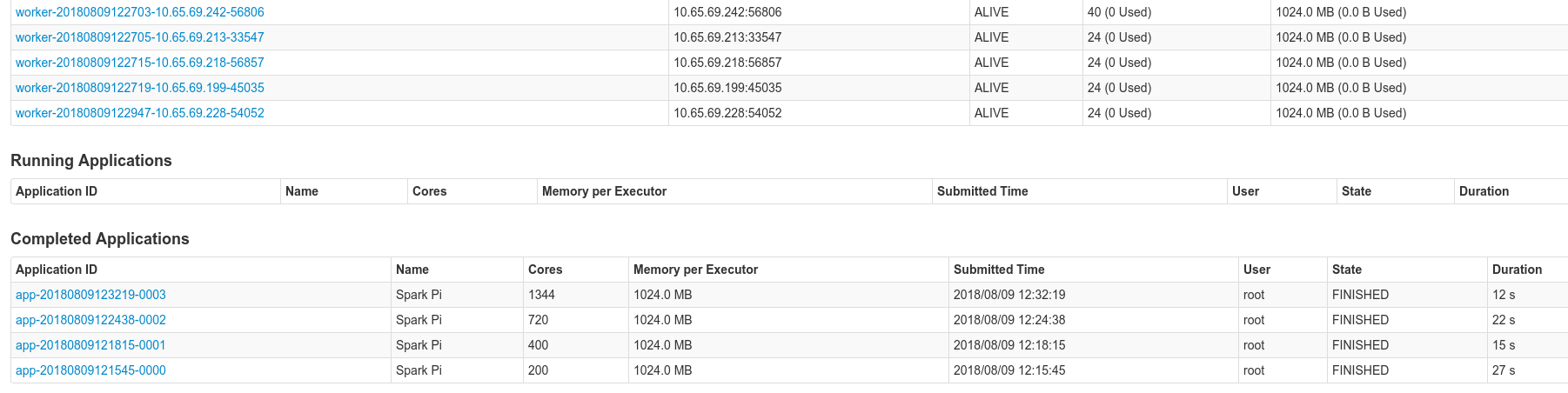
Schön auch zu sehen, dass die "Docker"-Container in Triton (in Wirklichkeit lx-branded Zones), dem Benutzer immer alle Cores der darunterliegenden Hardware anbieten, sodaß dieser sie nutzen kann, sofern sie nicht von anderen Prozessen oder Usern genutzt werden. Eine Erkenntnis aus diesem Test: Offenbar skaliert das Schätzen von Pi mit Spark nur bedingt.