Dieser Beitrag ist im November 2016 erschienen
Man kann leicht erkennen, dass der Betrieb von Applikationen, die ihren Zustand selbst verwalten (also "stateful" sind), in der Cloud eine besondere Herausforderung darstellt. Der Grund liegt auf der Hand: Es gibt "in der Cloud" eigentlich keinen Ort gibt, an dem man Daten "endgültig" abspeichern kann - alles ist "flüchtig". Selbstverständlich haben die Anbieter in diesem Bereich dieses Problem auch erkannt und es für Angebote von "Infrastructure as a Service" bereits gelöst. Bei AWS, Azure, GCE und Joyent gibt es verschiedene Arten von nicht-flüchtigem Speicher (Blockstorage, Objectstorage, etc.) zur Miete.
Leider ist die Benutzung von nicht-flüchtigem Speicher im Bereich der Docker-Container nicht so einfach. Docker kennt nur "Volumes". Die gab es bis vor Kurzem nur in zwei Ausprägungen:
Als Verzeichnis, welches man sich in seinen Docker-Container einblendet
$ docker run -d -P --name web -v /src/webapp:/webapp training/webapp python app.py |
Oder als Volume, welches man von einem "Datencontainer" nutzt
$ docker run -d -p 80:80 --volumes-from pmm-data --name pmm-server --restart always percona/pmm-server:1.0.5 |
Es ist klar, dass dieses Vorgehen in verteilten Umgebungen nur eingeschränkt funktionieren kann. Im ersten Fall haben Container, die auf einem anderen Docker-Host gestartet werden, keinen Zugriff auf das Volume (denn es liegt ja auf einem anderen Docker-Host) und im zweiten Fall können ebenfalls nur Container auf das Volume zugreifen, wenn sie auf demselben Docker-Host gestartet werden wie der "Datencontainer". Soll sich eine Docker-Umgebung über mehrere Hosts erstrecken und sollen die dort verwendeten Volumes an allen beteiligten Docker-Hosts verwendet werden können, muß eine andere Lösung her: Persistente Volumes.
Konkret geht es darum Containern, egal auf welchem Docker-Hosts sie gestartet werden, immer das von ihnen genutzte Volume (oder die genutzten Volumes - Container können auch mehrere nutzen) zur Verfügung zu stellen. Da die Live-Migration von Docker-Containern momentan noch nicht weit verbreitet ist, geht es meist um die Situation, die entsteht, wenn ein Docker-Host abstürzt oder nicht mehr verfügbar ist und damit die darauf laufenden Container auf einem anderen Docker-Host neu gestartet werden sollen.
Wenn man nur zustandslose Applikationen in Docker-Containern startet, ist das kein Problem. Die Applikation muß sich die Daten, die sie benötigt, eben beim (Neu)start von woanders laden. Wenn die erforderlichen Daten dem Container aber erhalten bleiben sollen, müssen die Daten auf persistenten Volumes abgelegt werden.
Da Kunden uns damit konfrontieren, stateful applications in Containern bei uns ausrollen zu wollen, müssen wir uns mit den Möglichkeiten der verschiedenen Orchestrierungsframeworks beschäftigen. Ein gutes Beispiel für eine solche Applikation scheint Wordpress zu sein, da es einerseits so weit verbreitet und beliebt ist, dass sich die Hersteller der Frameworks damit beschäftigen und andererseits aus mehreren verschiedenen Komponenten besteht, von denen wenigstens die Datenbank "stateful" behandelt werden muß. Ich habe mir also für
Beispiele für Wordpress-Deployments "herausgegoogelt" und nachgesehen, wie wirklichkeitsnah diese aussehen und wieviel Unterstützung das jeweilige Framework dem Entwickler und dem Systemadministrator bietet.
Wordpress auf Kubernetes
Im Beispiel Persistent Installation of MySQL and WordPress on Kubernetes, welches offenbar ca. acht Monate alt ist, wird offenbar die Google Compute Cloud benutzt - als persistent volume kommt deshalb eine GCE Persistent Disk zum Einsatz. Im Text findet sich aber auch der Link zur Kubernetes-Dokumentation, welche die verschiedenen Typen von persistent volumes auflistet, die derzeit von Kubernetes unterstützt werden. Für uns dürften am ehesten
- FC (Fibre Channel)
- NFS
- iSCSI
- RBD (Ceph Block Device)
- CephFS
- Cinder (OpenStack block storage)
- VsphereVolume
interessant sein. Leider endet das Beispiel schon nach dem Deployment einer MySQL- und einer Wordpress-Instanz. Was genau passieren soll, wenn man den MySQL-Container oder den Wordpress-Container "skaliert" (also weitere Instanzen davon startet - und ich dachte, das wäre der Sinn eines Orchestrierungsframeworks) wird nicht behandelt.
Mal sehen, was Wordpress Application Clustering using Kubernetes with HAProxy and Keepalived bietet. Der im Beispiel verwendete Kubernetes-Cluster sieht so aus:
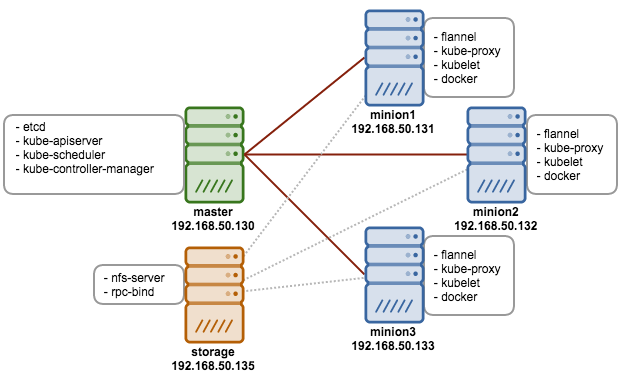
In diesem Beispiel wird für das persistente Volume NFS eingesetzt:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv5gweb
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /shared/kubernetes/web
server: 192.168.50.135
Dasselbe wird auch für die Datenablage der MySQL-DB eingerichtet. Im weiteren Verlauf dieses Beispiels werden zunächst leider wieder nur zustandslose Dienste "skalierbar" konfiguriert (z. B. werden gleich drei Instanzen des Wordpress-Containers über einen replication controller gestartet. Diese verwenden den obigen NFS-Mount als Datenablage). Weiterhin wird mit ha-proxy ein reverse-proxy gebaut, um das Wordpress-Konstrukt von aussen erreichbar zu machen. Zusätzlich ist dargestellt, wie man mit keepalived (ausserhalb von Containern und kubernetes) ausfallsicher eine VIP bereitstellen kann, die den Zugriff auf den reverse-proxy bereitstellt. Erst in den "Notes" wird auf einen Blogartikel hingewiesen, der den Betrieb eines Galera-Clusters in Kubernetes beschreiben soll. Leider handelt es sich nur um einen "proof of concept", der aber schön die Schwierigkeiten mit Portmapping und Docker unter Linux zeigt. Es ist nicht möglich per "Skalierung" zusätzliche Nodes in das Cluster aufzunehmen. Welcher Art die persistent volumes sind (oder ob überhaupt welche verwendet werden) wird leider nicht gesagt.
Um die fehlenden Funktionen nachzurüsten, hat Kubernetes kürzlich das Konzept der "Operators" vorgestellt (und gleich einen für etcd und einen für Prometheus vorgestellt). Nicht, dass es entsprechende Ansätze mit dem autopilot pattern und Habitat nicht schon geben würde. Aber das "not invented here" Syndrom scheint auch bei CoreOs durchaus nicht ganz unbekannt zu sein.
Es gibt einen neuen Versuch (diesmal mit Percona-Cluster und einem nicht redundanten NFS-Server) - habe ich in den Links schomal aufgenommen. Merker: Percona selbst sagt, dass man - wenn man einen Cluster über 10 Nodes skalieren will - mit Percona Kontakt aufnehmen soll. Hintergrund: Der Replikationstraffic nimmt natürlich mit jedem zusätzlichen Node zu. Als Alternative zu einen redundanten NFS-Server wird Ceph oder Gluster vorgeschlagen. Noch mehr Komplexität.
Wordpress auf Mesos
Das Beispiel in der Mesos-Dokumentation ist leider noch trauriger als die beiden oben aufgeführten Versuche mit Kubernetes. Immerhin erfahren wir mehr über die Verwendung des Marathon-Loadbalancers in Mesos. Leider wird kein Wort über persistente Volumes verloren. Stattdessen wird empfohlen, den Container auf einen bestimmten Node zu "pinnen", weil ein Host-Volume verwendet wird. "Skalierung" geht damit nicht.
Auch das Wordpress / MySQL example von Capgemini ist keine Hilfe. Hier werden i. W. MySQL und Wordpress per API deployed. Persistente Volumes oder Skalierung: Fehlanzeige.
Ein weiterer Blogeintrag sieht etwas vielversprechender aus. Auch hier soll ein Galera-Cluster als Wordpress-Backend verwendet werden. Ich bin mir allerdings nicht ganz sicher, wie stark automatisiert das Setup ist. Auf den ersten Blick hat es mich nicht überzeugt (z. B. der ssh-Login in den Cassandra-Node, um dort die entsprechenden Tabellen per Hand anzulegen).
Weitere Dokumentation auf github schildert die Verwendung von local persistent volumes, die ähnlich wie bei Datencontainern auf den Node gebunden sind und so erzwingen, dass alle Applikationen, die darauf zugreifen wollen, auch auf dem jeweiligen Node gestartet werden müssen.
Ein weiteres Projekt, welches persistente Volumes für Mesos bereitstellen will ist Flocker von Cluster-HQ. Der Kommentar "It is not built with production-readiness in mind." lässt mich allerdings gleich stutzen. Ein Blogeintrag von Cluster-HQ mit Videos schildert den Einsatz bei AWS mit einem EBS-Volume. Ein anderer Blogeintrag zeigt den Einsatz beim Re-Start einer MySQL-Instanz, um von langsamen Platten auf schnelle SSDs zu migrieren (in diesem Fall mit ZFS - auf der Flocker-Homepage wird allerdings nur EXT4 als unterstütztes Filesystem genannt?!). Flocker kümmert sich offensichtlich aber nur um das "Umhängen" der definierten Volumes. Welche Vorkehrungen getroffen wurden, um Fehlersituationen zu vermeiden (also wann welche Komponente entscheidet, ein Volume zu einem anderen Docker-Host umzuziehen) habe ich auf den ersten Blick nicht ermitteln können.
Wordpress in OpenShift
How To Automatically Scale WordPress on OpenShift bezieht sich leider noch auf OpenShift Online v2. Aber auch hier wird nur eine MySQL-Instanz installiert. Die "Skalierung" der Wordpress-Instanz wird interessanterweise ohne persistentes Volume und ohne NFS-Service - stattdessen wird S3 von Amazon bemüht, wo Uploads nach Wordpress abgespeichert werden. Die Inititalisierung einer Wordpress-Instanz geschieht über das git-Repo, welches in OpenShift dem Projekt zugeordnet wird.
Leider habe ich noch kein Wordpress-Beispiel für OpenShift 3.x gefunden. Da OpenShift auf Kubernetes basiert, gehe ich aber davon aus, dass die Unterstützung von persistenten Volumes ähnlich ausfällt wie bei Kubernetes selbst. Interessant wäre, ob OpenShift darüber hinaus noch Hilfen für die Skalierung von stateful applications bereithält.
Kleine Ergänzung: OpenShift ist im Grunde Kubernetes in Tateinheit mit OpenVSwitch. Darüber wird dort das SDN abgebildet.
Wordpress mit ContainerPilot
Es ist offensichtlich, dass das Setup, dass Joyent mit ContainerPilot gebaut hat, am weitesten entwickelt ist.

ContainerPilot verwendet ein Consul-Cluster als "source of truth" für alle Komponenten - keins der vorangegangenen Beispiele hat Service-Discovery verwendet. Die Skalierung von MySQL erfolgt nach dem Master/Slave-Konzept. Fällt z. B. der Master aus, wird automatisch einer der Slaves zum neuen Master gemacht. Datenbankbackups werden automatisch in einem Objectstore gespeichert. Obwohl shared-Storage in Triton eigentlich nicht vorkommt, steht ein NFS-Server bereit, und für nginx ist sogar die Versorgung mit ssl-Zertifikaten per Letsencrypt vorgesehen. Das Einzige, was in diesem Setup fehlt, ist ein Analog zum replication controller von Kubernetes, der dafür sorgt, dass immer eine vordefinierte Zahl an Containern läuft und ggfs. per Autoscaling für mehr Leistung sorgt. Joyent ist dabei, mit den vom ContainerPilot gelieferten Telemetriedaten und Prometheus ein solches System zu implementieren.
ContainerPilot kann in jedem Container eingesetzt werden - also auch mit Kubernetes und Mesos - wenn man diesen hohen Automatisierungsgrad bei stateful applications erreichen möchte, wird man es wohl müssen.
Links:
https://github.com/kubernetes/kubernetes/tree/master/examples/mysql-wordpress-pd
https://docs.mesosphere.com/1.9/usage/tutorials/wordpress/
https://docs.mesosphere.com/1.8/usage/tutorials/wordpress/
https://github.com/Capgemini/Apollo/tree/master/examples/wordpress-mysql
http://www.bigindustries.be/mashing-up-the-old-with-the-new-on-top-of-dcos/
https://mesosphere.github.io/marathon/docs/persistent-volumes.html
http://innerdot.com/containers/developing-a-stateful-application-on-mesos-and-docker
https://www.joyent.com/blog/nginx-and-letsencrypt-on-autopilot
https://www.joyent.com/blog/wordpress-on-autopilot-with-ssl
https://flocker-docs.clusterhq.com/en/latest/index.html
https://clusterhq.com/2015/10/06/marathon-ha-demo/
https://clusterhq.com/2015/08/28/flying-with-marathon/
https://github.com/openshift/wordpress-example
https://blog.openshift.com/12-tips-for-hosting-wordpress-on-openshift/
https://blog.openshift.com/how-to-automatically-scale-wordpress-on-openshift/
http://www.developer.com/lang/php/using-a-wordpress-quickstart-example-in-openshift.html
http://thenewstack.io/deploy-highly-available-wordpress-instance-statefulset-kubernetes-1-5/