Der Artikel ist im September 2019 erschienen
Kürzlich erfuhr ich bei einem Treffen mit einem unserer Kunden von dem Problem, dass Kunden mit einer "Private Cloud" und mit einem "Shared VCenter" keinen Zugriff auf Informationen haben, wie stark ihre ("eigenen") ESXi-Hosts eigentlich ausgelastet sind. Offenbar ist das "Shared VCenter" so konfiguriert, dass die genannten Informationen für Kunden nicht zugänglich sind. Es fehlt dem Kunden also eine wichtige Komponente, um sich selbst ein MAT(Monitoring, Alerting, Trending)-System aufzubauen. Es galt also zu erforschen, ob man "am VCenter vorbei" Kunden die gewünschten Informationen bereitstellen kann.
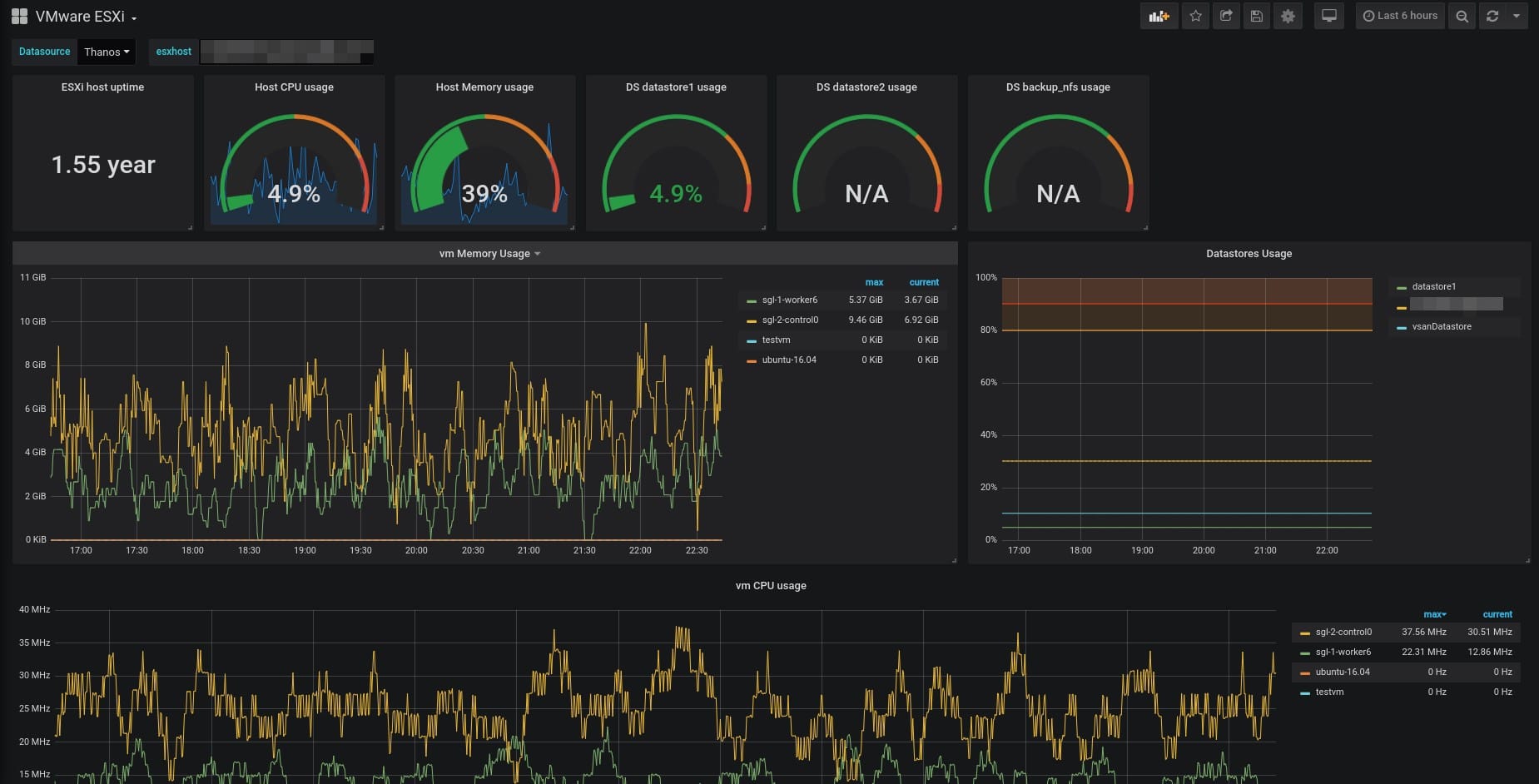
Natürlich ist dieses Problem bereits von vielen Anderen gelöst worden, denen das Angebot von VMWare in diesem Bereich nicht ins Konzept passte. Denn die dazu erforderlichen Komponenten sind frei verfügbar und ausgereift:
- Prometheus-VMWare-Exporter, Prometheus, Grafana
- Telegraf, InfluxDB, Chronograf, Kapacitor (der TICK Stack)
- Oder eine Mischlösung: Telegraf (mit Prometheus- und vSphere-Plugin), Prometheus, Grafana
Die erste Option läßt sich schnell umsetzen. Der prometheus-vmware-exporter muß aus dem Quelltext übersetzt werden. Wichtigste Voraussetzung: Eine Docker-Version verwenden, die multi-stage builds unterstützt (ab 17.05). Ist das Image erstellt, exportiert man schnell die erforderlichen Umgebungsvariablen und kann den Container starten:
root@7384294c-b9f9-657d-f7e5-ce9b11cd3120:~# env |grep ESX
ESX_PASSWORD=geheim
ESX_HOST=myesxi-host.com
ESX_LOG=debug
ESX_USERNAME=romonitoring
root@7384294c-b9f9-657d-f7e5-ce9b11cd3120:~# docker run -d -p 9512:9512 --restart=always --name=prometheus-vmware-exporter --env=ESX_HOST --env=ESX_USERNAME --env=ESX_PASSWORD --env=ESX_LOG prometheus-vmware-exporter
Ist das erledigt, kann man eine bestehende Prometheus-Instanz um eine entsprechende Scraping-Konfiguration erweitern:
- job_name: triton-lab
[...]
- job_name: esxi-lab
static_configs:
- targets: ['10.65.69.238:9512']
labels:
group: 'myesxi-host.com'
Da ich wissen wollte, ob der Container auch ohne Docker- und VM-Overhead in Triton läuft, habe ich ihn getagged, in meine Registry gepusht und dann auf Triton deployed. Läuft auch:
root@7384294c-b9f9-657d-f7e5-ce9b11cd3120:~# docker login -u myname -p geheim https://myreg.mydomain.net
root@7384294c-b9f9-657d-f7e5-ce9b11cd3120:~# docker tag prometheus-vmware-exporter myreg.mydomain.net/esxi/prometheus-vmware-exporter:2019092001
root@7384294c-b9f9-657d-f7e5-ce9b11cd3120:~# docker push myreg.mydomain.net/esxi/prometheus-vmware-exporter:2019092001
[...]
root@e3b75fc5-3621-cdd8-f9dd-c9acbf4a37e9:~# triton-docker login https://myreg.mydomain.net
root@e3b75fc5-3621-cdd8-f9dd-c9acbf4a37e9:~# . ./esxi.env
root@e3b75fc5-3621-cdd8-f9dd-c9acbf4a37e9:~# triton-docker run -d -p 9512:9512 --restart=always --name=prometheus-vmware-exporter --env=ESX_HOST --env=ESX_USERNAME --env=ESX_PASSWORD --env=ESX_LOG prometheus-vmware-exporter:2019092001
Danach im Grafana noch das passende Dasboard importieren. Fertig.
Wenn es aus Sicherheitsgründen ein Problem ist, dem Kunden direkten RO-Zugriff auf die Management-GUIs der ESXi-Server seiner Private-Cloud zu geben (weil z. B. alle Management-IPs aller ESXi-Server in einem DC im selben Management-Netz stehen), reicht es auch, ihm Zugriff auf die IPs der Docker-Container zu geben, die er dann der Konfiguration seines Prometheus-Servers hinzufügen würde.
Die dritte Option (Telegraf mit Prometheus- und vSphere-Plugin, Prometheus, Grafana) ist ähnlich einfach umzusetzen. Bei der Testinstallation von Telegraf, die ich auf Ubuntu vorgenommen habe, wird eine Konfigurationsdatei für Telegraf mitgeliefert, die alle relevanten Parameter schon enthält. Diese müssen einfach nur noch einkommentiert werden. Generell ist Telegraf modular aufgebaut: Input-Plugins bestimmen, welche Metriken Telegraf erhebt und die Output-Plugins bestimmen, wie und an welche Komponente Telegraf die Metriken weitergibt.
Für unseren Fall benötigen wir das vSphere Input Plugin - um die vom VCenter oder vom ESXi-Host eingesammelten Metriken von einem Prometheus-Server einsammeln zu lassen, benötigen wir noch das Prometheus-Output-Plugin.
Mit einer statischen Scraping-Konfiguration (wie oben) in der Prometheus-Konfiguration tauchen dann auch bald die vom Telegraf eingesammelten Daten in Prometheus auf
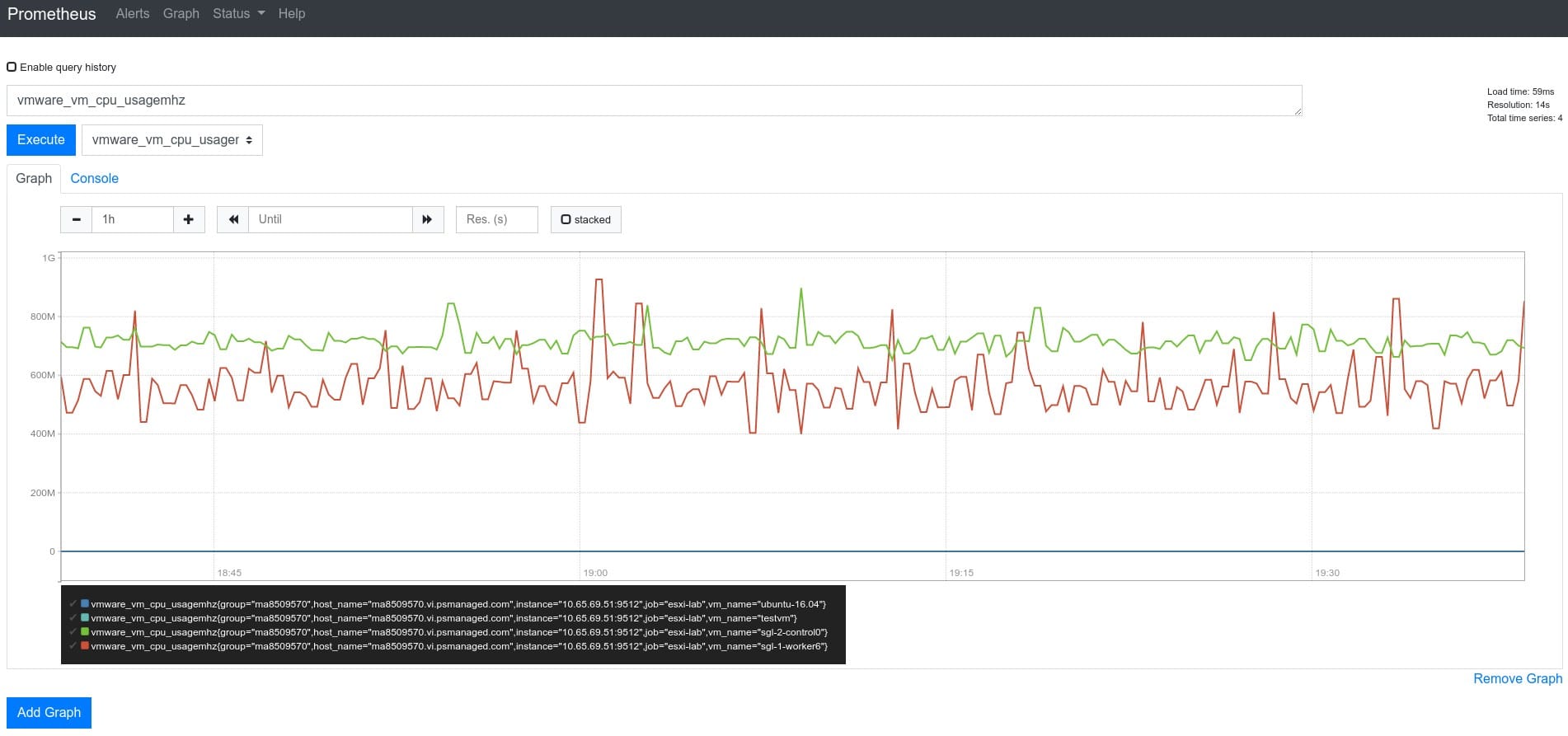
Leider haben die im Beispiel verwendeten Grafana Dashboards von Jorge de la Cruz InfluxDB zur Voraussetzung, sodaß man sie mit Prometheus bzw. Thanos als Datenquelle nicht sofort benutzen kann. Vielleicht kann man sie aber auch anpassen.
Interessant sind auch die weiteren Plugins für Telegraf. So sind in der Konfigurationsdatei auch Output-Plugins für Azure Application Insights, Azure Monitor, Google Cloud PubSub, AWS Cloudwatch, CrateDB, DataDog, Graphite, Kafka, Graylog, AWS Kinesis, MQTT, NATS, OpenTSDB, Google Stackdriver, Wavefront und viele weitere. Das Pluginkonzept macht Telegraf sehr flexibel und ist deshalb einen genaueren Blick wert. Telegraf gehört zum sogenannten TICK-Stack (zweite Option - s. o.), der aktuell von Influxdata als Alternative zu Prometheus und Grafana positioniert wird:
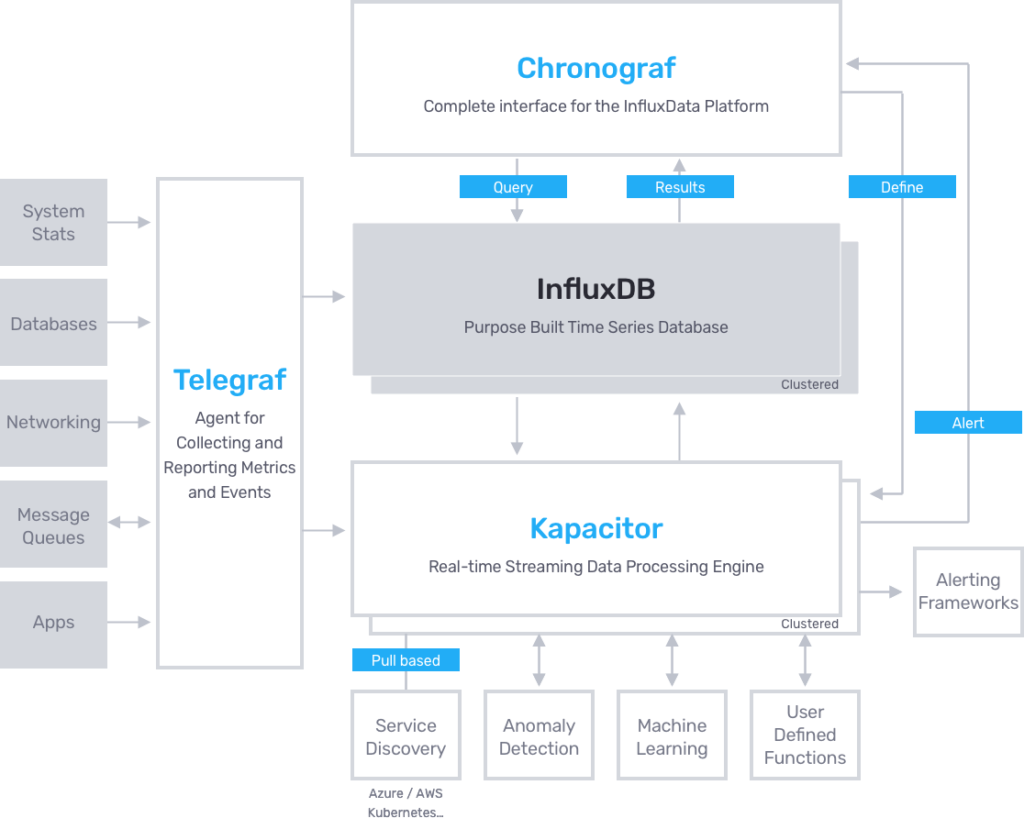
Influxdata verfolgt mit der InfluxDB ein "Open Core" Geschäftsmodell. Die OpenSource-Variante von InfluxDB unterstützt kein Clustering. Ein ausfallsicheres Setup mit InfluxDB ist derzeit also allenfalls mit InfluxDB-Enterprise möglich während für Prometheus mit Thanos und Cortex schon zwei (fast identische) Projekte existieren, die den Aufbau von ausfallsicheren Prometheus-Setups erlauben.
Links:
Grafana, Telegraf, Alerta – Prometheus besser nutzen
- prometheus-vmware-exporter und zugehöriges Grafana Dashboard
- VMWare vSphere - Overview Dashboard von Jorge de la Cruz (Github, Blog, Blogartikel)
vSphere Performance data - New vSphere plugin for Telegraf (Github)
How to Monitor VMware ESXi with Grafana and Telegraf
- Telegraf (Telegraf is a plugin-driven server agent for collecting and reporting metrics)
- InfluxDB (InfluxDB is a time series database built from the ground up to handle high write and query loads)
- Chronograf (Chronograf is the administrative user interface and visualization engine of the stack)
- Kapacitor (Kapacitor is a native data processing engine. It can process both stream and batch data from InfluxDB)
Alerting Microsoft Teams aus Grafana (Konfiguration eines Webhooks in Teams und dann von Alarmen in Grafana - dort ist Teams schon als Notification-Quelle vorhanden).
Weil mir gerade kein besserer Platz einfällt: Auch Java/Spring Boot Applikationen können mit Micrometer Metriken exportieren (alle, die die JVM anbietet), die von Prometheus (und auch Ganglia, Graphite, InfluxDB, New Relic, StatsD, Azure Application Insights, Elasticsearch, StackDriver etc.) konsumiert werden können.
Hier ein Beispiel mit Micrometer und Prometheus bei GitHub.